|
Sybaseでテーブル分割とその検証
Sybaseでテーブル分割とその検証
0.更新履歴
1.はじめに
このドキュメントでは,ASE11.0.3.3#ESD6にて,テーブル分割を行う手順と,そのパフォーマンスについて検証した結果について説明する.
なお,「テーブル分割」とは,Oracleでいうパーティションテーブルのことで,概略はドキュメント「テーブルのパーティション分割」を参照のこと.
2.今回作成するテーブル分割の説明
- 今回作成する分割するテーブルの保存先として,物理的に3つのデータベースファイル(デバイスファイル)を作成する.
- テーブル分割を行うと,Sybaseでは自動的にデータを配置する.
- テーブルの分割数と物理デバイスの数が一致していると,一番良い.
- 今回はテスト用なので,次のようなデバイスを作成する.
|
デバイス名 |
サイズ |
|
PTest1_dat01 |
5MB |
|
PTest1_dat02 |
5MB |
|
PTest1_dat03 |
5MB |
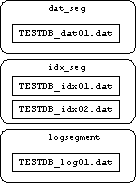
- これを作成しただけの状態だと,次のような構成となる.
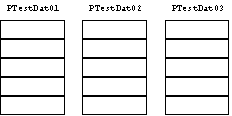
- この状態で,データを追加していくと,次のようなイメージでデータが追加されていく.
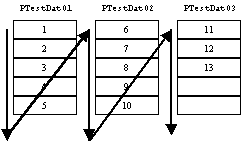
- つまり,PTestDat01のデータブロックが順番に消費され,格納する場所がなくなるとPTestDat02を消費するというイメージとなる.
- ここで,作成したテーブルを3つにテーブル分割を行うと,次のようなイメージとなる.
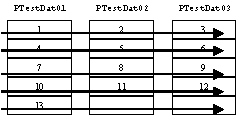
- データの書き込みが複数のデバイスに分散されるため,ホットスポットの削減や並列化が可能となるわけである.
3.準備
3.1.テスト用データベースの作成
- 実験に用いる,テスト用データベースとして,TESTDBを作成しておく.
- TESTDBを作成するには,以下のスクリプトを実行する.
bash$ cat CreateDB.TESTDB.sql
print 'Create TESTDB_dat01 5MB'
declare @vdevno int
select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
from master.dbo.sysdevices d, master.dbo.spt_values v
where v.type = 'E' and v.number = 3
disk init name='TESTDB_dat01',
physname='/opt/sybase/database/datdevice/TESTDB_dat01.dat',
vdevno = @vdevno ,
size=2560
go
print 'Create TESTDB_idx01 5MB'
declare @vdevno int
select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
from master.dbo.sysdevices d, master.dbo.spt_values v
where v.type = 'E' and v.number = 3
disk init name='TESTDB_idx01',
physname='/opt/sybase/database/idxdevice/TESTDB_idx01.dat',
vdevno = @vdevno ,
size=2560
go
print 'Create TESTDB_idx02 5MB'
declare @vdevno int
select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
from master.dbo.sysdevices d, master.dbo.spt_values v
where v.type = 'E' and v.number = 3
disk init name='TESTDB_idx02',
physname='/opt/sybase/database/idxdevice/TESTDB_idx02.dat',
vdevno = @vdevno ,
size=2560
go
print 'Create TESTDB_log01 5MB'
declare @vdevno int
select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
from master.dbo.sysdevices d, master.dbo.spt_values v
where v.type = 'E' and v.number = 3
disk init name='TESTDB_log01',
physname='/opt/sybase/database/logdevice/TESTDB_log01.dat',
vdevno = @vdevno ,
size=2560
go
print 'Create database TESTDB'
create database TESTDB
on
TESTDB_dat01 = 5,
TESTDB_idx01 = 5,
TESTDB_idx02 = 5
log on
TESTDB_log01 = 5
go
print 'Create Segment dat_seg'
use TESTDB
go
sp_addsegment dat_seg,TESTDB,TESTDB_dat01
go
print 'Create Segment idx_seg'
go
sp_addsegment idx_seg,TESTDB,TESTDB_idx01
go
sp_extendsegment idx_seg,TESTDB,TESTDB_idx02
go
print 'Drop Segment default & system'
go
sp_dropsegment "default",TESTDB,TESTDB_idx01
go
sp_dropsegment "default",TESTDB,TESTDB_idx02
go
sp_dropsegment system,TESTDB,TESTDB_idx01
go
sp_dropsegment system,TESTDB,TESTDB_idx02
go
go
print 'Set Database Option'
go
use master
go
print 'Set Database Option -- Bulkcopy on'
go
sp_dboption "TESTDB","select into/bulkcopy",true
go
checkpoint
go
print 'Set Database Option -- Trunc log on'
go
dump transaction TESTDB with no_log
go
sp_dboption "TESTDB","trunc log on chkpt",true
go
checkpoint
go
print 'Create user TESTDB'
go
use master
go
sp_addlogin test,testpass,TESTDB,japanese
go
sp_adduser test
go
use TESTDB
go
sp_changedbowner test
go
bash$
|
- TESTDBを確認してみると,次のような上体で作成されているはず.
1> sp_helpdb TESTDB
2> go
name db_size owner dbid
created
status
------------------ ------------- ----------- ------
-----------
-------------------------------------------------
TESTDB 20.0 MB test 6
Apr 22, 2002
select into/bulkcopy, trunc log on chkpt
device_fragments size usage free kbytes
------------------ ------- ----------- -----------
TESTDB_dat01 5.0 MB data only 4288
TESTDB_idx01 5.0 MB data only 5120
TESTDB_idx02 5.0 MB data only 5120
TESTDB_log01 5.0 MB log only 5104
(return status = 0)
1>
|
3.2.テーブル割用に使うデバイスとセグメントをを作成する
- テーブル分割を行うテーブルオブジェクトを格納する為のデバイスを用意する.
- ここでは,5MBのデバイス3つを作成して,そのデバイスをPTest_segというセグメント名として定義する手順を説明する.
- 次のようなスクリプトを使って,3つのデバイスを作成する.
print 'Create PTest_dat01 5MB'
declare @vdevno int
select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
from master.dbo.sysdevices d, master.dbo.spt_values v
where v.type = 'E' and v.number = 3
disk init name='PTest_dat01',
physname='/opt/sybase/database/datdevice/PTest_dat01.dat',
vdevno = @vdevno ,
size=2560
go
print 'Create PTest_dat02 5MB'
declare @vdevno int
select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
from master.dbo.sysdevices d, master.dbo.spt_values v
where v.type = 'E' and v.number = 3
disk init name='PTest_dat01',
physname='/opt/sybase/database/datdevice/PTest_dat02.dat',
vdevno = @vdevno ,
size=2560
go
print 'Create PTest_dat03 5MB'
declare @vdevno int
select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
from master.dbo.sysdevices d, master.dbo.spt_values v
where v.type = 'E' and v.number = 3
disk init name='PTest_dat03',
physname='/opt/sybase/database/datdevice/PTest_dat03.dat',
vdevno = @vdevno ,
size=2560
go
|
[sybase@poweredge sybase]$ isql -Usa -P -STESTDB -Jsjis -zjapanese
1> set language us_english
2> go
1> print 'Create PTest_dat01 5MB'
2> declare @vdevno int
3> select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
4> from master.dbo.sysdevices d, master.dbo.spt_values v
5> where v.type = 'E' and v.number = 3
6> disk init name='PTest_dat01',
7> physname='/opt/sybase/database/datdevice/PTest_dat01.dat',
8> vdevno = @vdevno ,
9> size=2560
10> go
Create PTest_dat01 5MB
(1 row affected)
1> print 'Create PTest_dat02 5MB'
2> declare @vdevno int
3> select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
4> from master.dbo.sysdevices d, master.dbo.spt_values v
5> where v.type = 'E' and v.number = 3
6> disk init name='PTest_dat02',
7> physname='/opt/sybase/database/datdevice/PTest_dat02.dat',
8> vdevno = @vdevno ,
9> size=2560
10> go
Create PTest_dat02 5MB
(1 row affected)
1> print 'Create PTest_dat03 5MB'
2> declare @vdevno int
3> select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
4> from master.dbo.sysdevices d, master.dbo.spt_values v
5> where v.type = 'E' and v.number = 3
6> disk init name='PTest_dat03',
7> physname='/opt/sybase/database/datdevice/PTest_dat03.dat',
8> vdevno = @vdevno ,
9> size=2560
10> go
Create PTest_dat03 5MB
(1 row affected)
1>
|
1> alter database TESTDB
2> on
3> PTest_dat01 = 5,
4> PTest_dat02 = 5,
5> PTest_dat03 = 5
6> go
Extending database by 2560 pages on disk PTest_dat01
Extending database by 2560 pages on disk PTest_dat02
Extending database by 2560 pages on disk PTest_dat03
1>
|
- 作成した3つのデバイス上に,PTest_segを作成する.
1> use TESTDB
2> go
1> sp_addsegment PTest_seg,TESTDB,PTest_dat01
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment created.
(return status = 0)
1> sp_extendsegment PTest_seg,TESTDB,PTest_dat02
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment extended.
(return status = 0)
1> sp_extendsegment PTest_seg,TESTDB,PTest_dat03
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment extended.
(return status = 0)
1>
|
- 作成した3つのデバイス上から,defaultセグメントを削除する.
1> sp_dropsegment "default",TESTDB,PTest_dat01
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment "default",TESTDB,PTest_dat02
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment "default",TESTDB,PTest_dat03
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1>
|
- 作成した3つのデバイス上から,systemセグメントを削除する.
1> sp_dropsegment system,TESTDB,PTest_dat01
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment system,TESTDB,PTest_dat02
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment system,TESTDB,PTest_dat03
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1>
|
1> sp_helpsegment
2> go
segment name status
------- ------------------- ------
0 system 0
1 default 1
2 logsegment 0
3 dat_seg 0
4 idx_seg 0
5 PTest_seg 0
(return status = 0)
1> sp_helpsegment PTest_seg
2> go
segment name status
------- -------------------- ------
5 PTest_seg 0
device size free_pages
-------------------- -------- -----------
PTest_dat01 5.0MB 2560
PTest_dat02 5.0MB 2560
PTest_dat03 5.0MB 2560
(return status = 0)
1>
|
- PTest_segが出来た模様.
- この時点でのデータベースの構成状態は,次のとおりである.
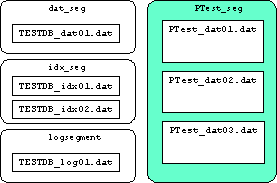
- PTest_segセグメントは,3つのデバイスファイルから構成されている.
3.3.ノーマルのデバイスとセグメントを作成する
- パーティション分割を行わないテーブルオブジェクトを格納する為のデバイスを作成する.
1> print 'Create NTest_dat01 5MB'
2> declare @vdevno int
3> select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
4> from master.dbo.sysdevices d, master.dbo.spt_values v
5> where v.type = 'E' and v.number = 3
6> disk init name='NTest_dat01',
7> physname='/opt/sybase/database/datdevice/NTest_dat01.dat',
8> vdevno = @vdevno ,
9> size=2560
10> go
Create NTest_dat01 5MB
(1 row affected)
1> print 'Create NTest_dat02 5MB'
2> declare @vdevno int
3> select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
4> from master.dbo.sysdevices d, master.dbo.spt_values v
5> where v.type = 'E' and v.number = 3
6> disk init name='NTest_dat02',
7> physname='/opt/sybase/database/datdevice/NTest_dat02.dat',
8> vdevno = @vdevno ,
9> size=2560
10> go
Create NTest_dat03 5MB
(1 row affected)
1> print 'Create NTest_dat03 5MB'
2> declare @vdevno int
3> select @vdevno = max(convert(tinyint, substring(convert(binary(4),d.low), v.low,1))) + 1
4> from master.dbo.sysdevices d, master.dbo.spt_values v
5> where v.type = 'E' and v.number = 3
6> disk init name='NTest_dat03',
7> physname='/opt/sybase/database/datdevice/NTest_dat03.dat',
8> vdevno = @vdevno ,
9> size=2560
10> go
Create NTest_dat03 5MB
(1 row affected)
1>
|
1> alter database TESTDB
2> on
3> NTest_dat01 = 5,
4> NTest_dat02 = 5,
5> NTest_dat03 = 5
6> go
Extending database by 2560 pages on disk NTest_dat01
Extending database by 2560 pages on disk NTest_dat02
Extending database by 2560 pages on disk NTest_dat03
1>
|
- 作成した3つのデバイス上に,PTest_segを作成する.
1> use TESTDB
2> go
1> sp_addsegment PTest_seg,TESTDB,NTest_dat01
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment created.
(return status = 0)
1> sp_extendsegment PTest_seg,TESTDB,NTest_dat02
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment extended.
(return status = 0)
1> sp_extendsegment PTest_seg,TESTDB,NTest_dat03
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment extended.
(return status = 0)
1>
|
- 作成した3つのデバイス上から,defaultセグメントを削除する.
1> sp_dropsegment "default",TESTDB,NTest_dat01
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment "default",TESTDB,NTest_dat02
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment "default",TESTDB,NTest_dat03
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1>
|
- 作成した3つのデバイス上から,systemセグメントを削除する.
1> sp_dropsegment system,TESTDB,NTest_dat01
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment system,TESTDB,NTest_dat02
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1> sp_dropsegment system,TESTDB,NTest_dat03
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Segment reference to device dropped.
(return status = 0)
1>
|
1> sp_helpsegment
2> go
segment name status
------- ------------------- ------
0 system 0
1 default 1
2 logsegment 0
3 dat_seg 0
4 idx_seg 0
5 PTest_seg 0
6 NTest_seg 0
(return status = 0)
1> sp_helpsegment NTest_seg
2> go
segment name status
------- -------------------- ------
5 NTest_seg 0
device size free_pages
-------------------- -------- -----------
NTest_dat01 5.0MB 2560
NTest_dat02 5.0MB 2560
NTest_dat03 5.0MB 2560
(return status = 0)
1>
|
- PTest_segが出来た模様.
- ここまでの作業により,データベースは次のような構成となる.
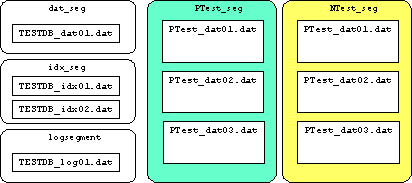
- ここまでの作業までは,普通のセグメントを作成する方法と変わりはない.
3.4.PTest_segセグメントに,分割したテーブルを作成してみる
1> create table TestTable
2> (
3> fieldA numeric(10,0) identity,
4> fieldB char(10)
5> ) on PTest_seg
6> go
1>
|
1> sp_help TestTable
2> go
Name Owner
Type
------------------------------ ------------------------------
----------------------
TestTable dbo
user table
Data_located_on_segment When_created
------------------------------ --------------------------
PTest_seg Apr 22 2002 8:14PM
Column_name Type Length Prec Scale Nulls Default_name
Rule_name Identity
--------------- --------------- ------ ---- ----- ----- ---------------
--------------- --------
fieldA numeric 6 10 0 0 NULL
NULL 1
fieldB char 10 NULL NULL 0 NULL
NULL 0
Object does not have any indexes.
No defined keys for this object.
Object is not partitioned.
(return status = 0)
1>
|
- "Object is not partitioned"となっているので,テーブル分割されていない事がわかる.
- これまでの状態では,次の図のようになる.
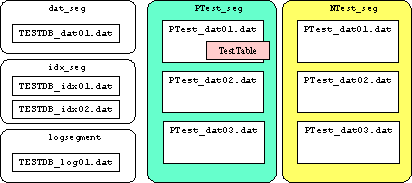
- alter table文で,作成したテーブル分割を行う.
1> alter table TestTable partition 3
2> go
1>
|
- alter table partitionを行う事で,各デバイスに分割されてテーブルが格納される.
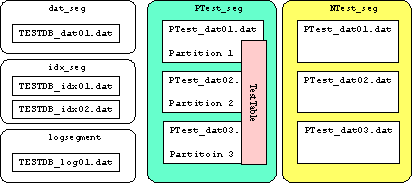
1> sp_help TestTable
2> go
Name Owner
Type
------------------------------ ------------------------------
----------------------
TestTable dbo
user table
Data_located_on_segment When_created
------------------------------ --------------------------
PTest_seg Apr 22 2002 8:14PM
Column_name Type Length Prec Scale Nulls Default_name
Rule_name Identity
--------------- --------------- ------ ---- ----- ----- ---------------
--------------- --------
fieldA numeric 6 10 0 0 NULL
NULL 1
fieldB char 10 NULL NULL 0 NULL
NULL 0
Object does not have any indexes.
No defined keys for this object.
partitionid firstpage controlpage
----------- ----------- -----------
1 10242 10243
2 12801 12802
3 15361 15362
(return status = 0)
1>
|
3.5.NTest_segに,普通にテーブルを作成してみる
- TestTableNとして,構造が同じテーブルを,NTest_segセグメントに作成する.
1> create table TestTableN
2> (
3> fieldA numeric(10,0) identity,
4> fieldB char(10)
5> ) on NTest_seg
6> go
1>
|
1> sp_help TestTableN
2> go
Name Owner
Type
------------------------------ ------------------------------
----------------------
TestTableN dbo
user table
Data_located_on_segment When_created
------------------------------ --------------------------
NTest_seg Apr 23 2002 5:20PM
Column_name Type Length Prec Scale Nulls Default_name
Rule_name Identity
--------------- --------------- ------ ---- ----- ----- ---------------
--------------- --------
fieldA numeric 6 10 0 0 NULL
NULL 1
fieldB char 10 NULL NULL 0 NULL
NULL 0
Object does not have any indexes.
No defined keys for this object.
Object is not partitioned.
(return status = 0)
1>
|
4.直列時の計測テスト
この章での計測方法は,1プロセスだけでデータベースにI/O負荷をかけ,未分割のテーブルと分割テーブルの性能差について検証する.
4.1.直列でinsert文でデータ投入してみる
1> set nocount on
2> go
1> declare @c1 int
2> select @c1 = 1
3> print "Start"
4> select convert(char(12),getdate(),108)
5> while @c1 < 5000
6> begin
7> insert into TestTable values("aaa")
8> select @c1 = @c1 + 1
9> end
10> print "End"
11> select convert(char(12),getdate(),108)
12> go
Start
------------
17:58:35
End
------------
17:59:22
1>
|
- 47秒.
- テーブル分割していないテーブルにデータを投入する.
1> declare @c1 int
2> select @c1 = 1
3> print "Start"
4> select convert(char(12),getdate(),108)
5> while @c1 < 5000
6> begin
7> insert into TestTableN values("aaa")
8> select @c1 = @c1 + 1
9> end
10> print "End"
11> select convert(char(12),getdate(),108)
12> go
Start
------------
18:05:40
End
------------
18:06:26
1>
|
- 46秒.
- 微妙ではあるが,分割を行っていないほうが速い.
- これは,他の要求が無いため,本来なら連続してデータを書き込めるはずが,テーブル分割しているため,書き込み対象のデバイスファイルをスイッチして移動しているためのオーバヘッドではないかと考える.
4.2.直列でデータを削除してみる
- テーブル分割を行っているテーブルのデータを削除する.
1> select convert(char(12),getdate(),108)
2> delete TestTableN
3> select convert(char(12),getdate(),108)
4> go
------------
18:09:10
------------
18:09:12
1>
|
- 2秒.
- テーブル分割を行っていないテーブルのデータを削除する.
1> select convert(char(12),getdate(),108)
2> delete TestTable
3> select convert(char(12),getdate(),108)
4> go
------------
18:08:50
------------
18:08:51
1>
|
4.3.直列時テストのまとめ
- 直列時の処理では,テーブルを分割していない方が高速だと考えられる.
- オンライン処理が止まり,1つのバッチ処理だけが稼動している夜間等によく使われるテーブルの場合は,分割しないほうが良いかもしれない.
5.並列実行検証
- 前出のように,単一で稼動している場合は,テーブル分割を行ったテーブルでのデータ追加処理は遅かった.
- よって,並列にプログラムを実行してデータ追加を行う処理を実行してみたいとおもう.
5.1.プログラムを準備する
- 次のようなTransact-SQLが書かれたファイルを作成する.
insertTable.sql
bash$ cat insertTable.sql
declare @c1 int
select @c1 = 1
print "Start"
while @c1 < 5000
begin
insert into TestTableN values("aaa")
select @c1 = @c1 + 1
end
print "End"
go
bash$
|
- 次のようにisql文を実行するシェルスクリプトを作成する.
insertTable.sh
bash$ cat insertTable.sh
date
isql -Utest -Ptestpass -STESTDB -iinsertTable.sql -Jsjis -zjapanese -olog.txt
date
bash$
|
- 作成したらパーミッションXをつけておく.
- 次のように,isql文を実行するシェルスクリプトを複数実行するシェルスクリプトを作成する.
insertTable.Multi.sh
bash$ cat insertTable.Multi.sh
insertTable.sh &
insertTable.sh &
insertTable.sh &
insertTable.sh &
insertTable.sh &
bash$
|
5.2.シェルを実行してみる
- 作成したシェルを実行して,ノーマルの場合の計測を行う.
[sybase@poweredge sybase]$ insertTable.Multi.sh
Tue Apr 23 18:33:09 JST 2002
Tue Apr 23 18:33:09 JST 2002
Tue Apr 23 18:33:09 JST 2002
Tue Apr 23 18:33:09 JST 2002
Tue Apr 23 18:33:09 JST 2002
Tue Apr 23 18:37:02 JST 2002
Tue Apr 23 18:37:03 JST 2002
Tue Apr 23 18:37:03 JST 2002
Tue Apr 23 18:37:03 JST 2002
Tue Apr 23 18:37:03 JST 2002
[sybase@poweredge sybase]$
|
- 234秒.
- 次に,SQL文のファイルに書かれた内容で,テーブル名を変更して次のような文を作成する.
修正したinsertTableN.sql
bash$ cat insertTableN.sql
declare @c1 int
select @c1 = 1
print "Start"
while @c1 < 5000
begin
insert into TestTable values("aaa")
select @c1 = @c1 + 1
end
print "End"
go
bash$
|
- テーブル分割したテーブルに変更した.
- 再度実行する.
[sybase@poweredge sybase]$ insertTableN.Multi.sh
Tue Apr 23 18:41:00 JST 2002
Tue Apr 23 18:41:00 JST 2002
Tue Apr 23 18:41:00 JST 2002
Tue Apr 23 18:41:00 JST 2002
Tue Apr 23 18:41:00 JST 2002
Tue Apr 23 18:42:28 JST 2002
Tue Apr 23 18:42:28 JST 2002
Tue Apr 23 18:42:29 JST 2002
Tue Apr 23 18:42:29 JST 2002
Tue Apr 23 18:42:29 JST 2002
[sybase@poweredge sybase]$
|
テーブル分割していないテーブル
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
なし1回目 |
18:33:09 |
18:37:03 |
00:03:54 |
234 |
|
なし2回目 |
18:57:06 |
19:01:01 |
00:03:55 |
235 |
|
なし3回目 |
19:04:37 |
19:08:31 |
00:03:54 |
234 |
|
平均 |
234 |
テーブル分割したテーブル
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
分割1回目 |
18:41:00 |
18:42:29 |
00:01:29 |
89 |
|
分割2回目 |
18:45:31 |
18:46:59 |
00:01:28 |
88 |
|
分割3回目 |
18:51:33 |
18:53:02 |
00:01:29 |
89 |
|
平均 |
89 |
- 予想通り,テーブル分割したテーブルのパフォーマンスが圧倒的に高い.
- パーティションを複数持つ事で,これはホットスポットの競合(取り合い)が削減され,同時実効性が高いという「テーブルのパーティション分割」で定義された理論に一致する.
6.並列化の度合いを確かめてみる(分割したテーブル)
- ここでは,並列に実行するプロセスを,1プロセス,5プロセス,10プロセスとした場合の速度の違いについて調査する.
6.1.テーブル分割したテーブルで,1プロセス
テーブル分割したテーブル 1プロセス
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
1個1回目 |
19:36:38 |
19:37:25 |
00:00:47 |
47 |
|
1個2回目 |
19:41:59 |
19:42:46 |
00:00:47 |
47 |
|
1個3回目 |
19:44:15 |
19:45:02 |
00:00:47 |
47 |
|
平均 |
47 |
- 5000行×1プロセス=5000行となるので,0.0094秒/行,47秒/5000行となる.
6.2.テーブル分割したテーブルで,5プロセス
テーブル分割したテーブル 5プロセス並列
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
5個1回目 |
18:41:00 |
18:42:29 |
00:01:29 |
89 |
|
5個2回目 |
18:45:31 |
18:46:59 |
00:01:28 |
88 |
|
5個3回目 |
18:51:33 |
18:53:02 |
00:01:29 |
89 |
|
平均 |
89 |
- 5000行×5プロセス=25000行となるので,0.00356秒/行,17.8秒/5000行となる.
- 並列度が無い1プロセス時に比べ,3倍も速くなった.
6.3.テーブル分割したテーブルで,10プロセス
テーブル分割したテーブル 10プロセス並列
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
10個1回目 |
19:14:44 |
19:17:41 |
00:02:57 |
177 |
|
10個2回目 |
19:25:26 |
19:28:23 |
00:02:57 |
177 |
|
10個3回目 |
19:28:35 |
19:31:32 |
00:02:57 |
177 |
|
平均 |
177 |
- 5000行×10プロセス=50000行となるので,0.00354秒/行,17.7秒/5000行となる.
- 実行速度は5プロセス時と比べても,ほぼ同じ値となっており,行あたりのレスポンスの劣化は無い.
7.並列化の度合いを確かめてみる(分割してないテーブル)
7.1.テーブル分割してないテーブルで,1プロセス
テーブル分割していないテーブル 1プロセス
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
1個1回目 |
19:48:06 |
19:48:52 |
00:00:46 |
46 |
|
1個2回目 |
19:52:43 |
19:53:30 |
00:00:47 |
47 |
|
1個3回目 |
19:57:41 |
19:58:27 |
00:00:46 |
46 |
|
平均 |
46 |
- 5000行×1プロセス=5000行となるので,0.0092秒/行,46秒/5000行.
7.2.テーブル分割してないテーブルで,5プロセス
テーブル分割していないテーブル 5プロセス
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
なし1回目 |
18:33:09 |
18:37:03 |
00:03:54 |
234 |
|
なし2回目 |
18:57:06 |
19:01:01 |
00:03:55 |
235 |
|
なし3回目 |
19:04:37 |
19:08:31 |
00:03:54 |
234 |
|
平均 |
234 |
- 5000行×5プロセス=25000行となるので,0.00936秒/行,46.8秒/5000行
- 実行時間は,1プロセスで行っているときと変化が無い.
7.3.テーブル分割してないテーブルで,10プロセス
テーブル分割していないテーブル 10プロセス
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
10個1回目 |
20:00:11 |
20:08:00 |
00:07:49 |
469 |
|
10個2回目 |
20:12:28 |
20:20:17 |
00:07:49 |
469 |
|
10個3回目 |
20:22:44 |
20:30:33 |
00:07:49 |
469 |
|
平均 |
469 |
- 5000行×10プロセス=50000行となるので,0.00938秒/行,46.9秒/5000行.
- これも1プロセスで行っているときと変化が無い.
8.データベースエンジンを2つにしてさらに並列度を増してみる
- 今回の検証を行っているサーバマシンは,2CPUマシンのため,これを生かすためにデータベースエンジンを2つ起動して,並列化し,データの投入パフォーマンスについて検証してみる.
8.1.データベースエンジンを2つにする
bash$ isql -Usa -P -STESTDB -Jsjis -zjapanese
1> sp_configure "max online engine"
2> go
Parameter Name Default Memory Used Config Value Run Value
------------------------------ ----------- ----------- ------------ -----------
max online engines 1 56 1 1
(return status = 0)
1>
|
- エンジンは1つで稼動している.
- エンジン数を2つに設定する.
1> sp_configure "max online engine",2
2> go
Parameter Name Default Memory Used Config Value Run Value
------------------------------ ----------- ----------- ------------ -----------
max online engines 1 56 2 1
Configuration option changed. The SQL Server must be rebooted before the change
in effect since the option is static.
(return status = 0)
1> quit
bash$
|
- Config Valueを見ると変更された事がわかる.
- ただし,再起動を要する.
- ここで,いったんデータベースをシャットダウンし,再起動する.
- 再起動後,接続してエンジン数を確認する.
bash$ isql -Usa -P -STESTDB -Jsjis -zjapanese
1> sp_configure "max online engine"
2> go
Parameter Name Default Memory Used Config Value Run Value
------------------------------ ----------- ----------- ------------ -----------
max online engines 1 111 2 2
(return status = 0)
1>
|
- Run Valueが2に設定されており,2エンジンで稼動している.
- showserverコマンドで2つエンジンが起動しているか確認する.
bash$ showserver
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
sybase 2258 1.8 20.9 787936 135632 ? S 21:16 0:01 dataserver
sybase 2259 0.0 0.7 7708 4888 pts/2 S 21:16 0:00 backupserver
sybase 2260 0.1 0.7 787920 4816 ? S 21:16 0:00 dataserver
bash$
|
- 2つのdataserverプロセスが稼動していることがわかる.
8.2.データ分割したテーブルで,5プロセス(2エンジン)
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
5個1回目 |
21:23:46 |
21:25:17 |
00:01:31 |
91 |
|
5個2回目 |
21:28:50 |
21:30:20 |
00:01:30 |
90 |
|
5個3回目 |
21:38:54 |
21:40:24 |
00:01:30 |
90 |
|
平均 |
90 |
- 1エンジンの時は89秒平均だったが,90〜91秒と若干パフォーマンスが落ちた.
- これは,このテストが,CPU処理を多く使うものではなく,I/Oばかりのため,逆にエンジン間(プロセス間)でI/Oのタイミングを合わせる処理のオーバヘッドが作用していると考えら得る.
8.3.データ分割してないテーブルで,5プロセス(2エンジン)
|
開始時間 |
終了時間 |
実行時間 |
実行時間(秒) |
|
5個1回目 |
22:07:23 |
22:11:18 |
00:03:55 |
235 |
|
5個2回目 |
22:11:50 |
22:15:44 |
00:03:54 |
234 |
|
5個3回目 |
22:17:38 |
22:21:33 |
00:03:55 |
235 |
|
平均 |
235 |
- 1エンジンの時は235秒だったので,あまり変化が無い.
- これはCPU性能というより,主にI/O待ちがネックになっている為,エンジンを増やしたところでパフォーマンス改善につながっていない事がわかる.
9.まとめ
- データ追加が頻繁に行われるテーブルに対して,テーブル分割を行うとパフォーマンスに効果がある.
- ただし,なんでもかんでもテーブル分割してしまうと,逆効果になる可能性がある.
- I/O部分の強化なので,CPU数が増えても意味が無い.
ご参考
|
|