



ブログ - システム障害事故カテゴリのエントリ
日本が,ゴールデンウィークに入ってからこの案内がメールで来たので,一部?のインフラエンジニアとかSREとか呼ばれる人たちが騒いでいる模様.
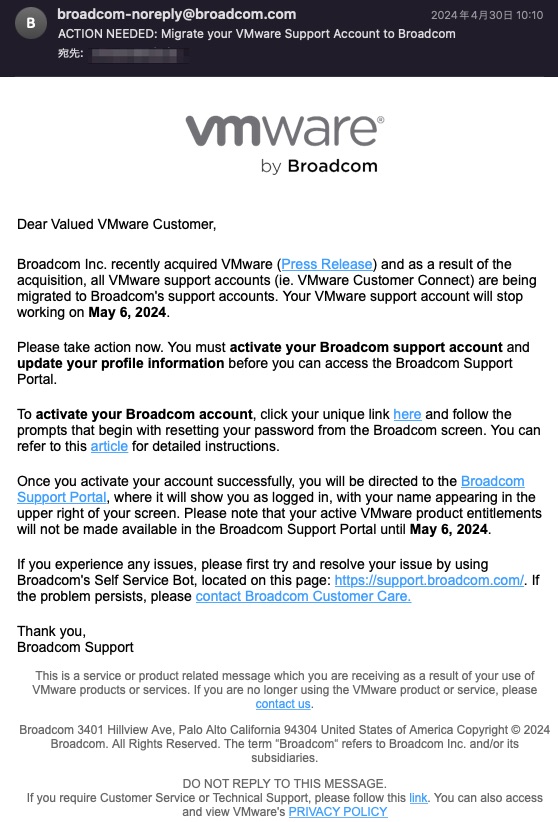
引用: 移行期限が5月6日だと考えた一般ユーザが注意喚起してツイートしているが,中の人っぽい人が「VMware Customer Connect が 5/6 に停止され、5/6 以降は Broadcom Support Portal でライセンス管理することになるからアクティベートしてください、というメールです」としています.
BroadcomはSymantecを買収し時にちょっと悪評があったりサポートが不通・遅延して困った思い出もあり,みんな困っている模様.ゴールデンウィークというのは日本独自の事情(でも中国でも連休中らしいけど)だけど,実質1週間しか猶予がないように取れるメールを送ってくるのがよくないのだろう.日本人エンジニアの英文読解力が良くないという批判もあるけど,日米企業の文化の差だろうね.
ちなみに自分のメールを見てみたけど,VMwareからは"Save the Date for VMware Explore 2024"という発表会の案内が4月1日に受信している以外,しばらく連絡がなかったようだから,予告なく今回の連絡という部分でビックリなのだろう.
引用:
ACTION NEEDED: Migrate your VMware Support Account to Broadcom
Dear Valued VMware Customer,
Broadcom Inc. recently acquired VMware (Press Release) and as a result of the acquisition, all VMware support accounts (ie. VMware Customer Connect) are being migrated to Broadcom's support accounts. Your VMware support account will stop working on May 6, 2024.
Please take action now. You must activate your Broadcom support account and update your profile information before you can access the Broadcom Support Portal.
To activate your Broadcom account, click your unique link here and follow the prompts that begin with resetting your password from the Broadcom screen. You can refer to this article for detailed instructions.
Once you activate your account successfully, you will be directed to the Broadcom Support Portal, where it will show you as logged in, with your name appearing in the upper right of your screen. Please note that your active VMware product entitlements will not be made available in the Broadcom Support Portal until May 6, 2024.
If you experience any issues, please first try and resolve your issue by using Broadcom's Self Service Bot, located on this page: https://support.broadcom.com/. If the problem persists, please contact Broadcom Customer Care.
Thank you,
Broadcom Support
VMwareをご愛用のお客様各位
この度、Broadcom Inc.はVMwareを買収いたしました(プレスリリース)。買収に伴い、VMwareのすべてのサポートアカウント(VMware Customer Connectなど)はBroadcomのサポートアカウントに移行されます。お客様の VMware サポートアカウントは、2024 年 5 月 6 日に機能停止となります。
今すぐご対応ください。Broadcom サポート ポータルにアクセスするには、Broadcom サポート アカウントを有効化し、プロフィール情報を更新する必要があります。
Broadcom アカウントをアクティブにするには、ここで固有のリンクをクリックし、Broadcom の画面からパスワードのリセットから始まるプロンプトに従ってください。詳細な手順については、この記事を参照してください。
BroadcomはSymantecを買収し時にちょっと悪評があったりサポートが不通・遅延して困った思い出もあり,みんな困っている模様.ゴールデンウィークというのは日本独自の事情(でも中国でも連休中らしいけど)だけど,実質1週間しか猶予がないように取れるメールを送ってくるのがよくないのだろう.日本人エンジニアの英文読解力が良くないという批判もあるけど,日米企業の文化の差だろうね.
ちなみに自分のメールを見てみたけど,VMwareからは"Save the Date for VMware Explore 2024"という発表会の案内が4月1日に受信している以外,しばらく連絡がなかったようだから,予告なく今回の連絡という部分でビックリなのだろう.
読売新聞の記事見出し「江崎グリコ「プッチンプリン」など冷蔵品のほぼ全品出荷停止、物流・調達システムに障害…5月中旬の再開目指す」が良くて気になって読んでしまったけど,SAP S/4HANAのバージョンアップ失敗が原因の模様.
江崎グリコの基幹システム移行トラブルについてまとめてみた
https://piyolog.hatenadiary.jp/entry/2024/04/26/013037
チルド商品を先に出荷停止したのは良い判断という意見もある.確かに冷蔵商品の管理ができない状態だと安全性に問題が出てもおかしくないし.

近所のスーパーでも思いっきりシステムトラブルと書かれてる
システム移行方式は「一括移行」「段階的移行」「並行運用」とあるけど,「一括移行」で対策前進だけだったのかな.システム移行プロジェクトは1年以上遅延していたから,コストが安いとされている一括移行を選んで,失敗したという経営判断だろう.
江崎グリコの基幹システム移行トラブルについてまとめてみた
https://piyolog.hatenadiary.jp/entry/2024/04/26/013037
チルド商品を先に出荷停止したのは良い判断という意見もある.確かに冷蔵商品の管理ができない状態だと安全性に問題が出てもおかしくないし.
近所のスーパーでも思いっきりシステムトラブルと書かれてる
システム移行方式は「一括移行」「段階的移行」「並行運用」とあるけど,「一括移行」で対策前進だけだったのかな.システム移行プロジェクトは1年以上遅延していたから,コストが安いとされている一括移行を選んで,失敗したという経営判断だろう.
新しい人が着任すると起こりがちな問題のやつ? 稀にたまに頻繁に見かける季節性トラブル.
人的ミスで利用者に影響が 那覇市役所でシステム障害
https://www.qab.co.jp/news/20240401206783.html
引用:
人的ミスで利用者に影響が 那覇市役所でシステム障害
https://www.qab.co.jp/news/20240401206783.html
引用:
那覇市によりますと、2024年4月1日午前9時半ごろから、市役所内のネットワークでシステム障害が発生しました。庁舎内では、転出届の受け付けを除いて、業務システムだけでなく、メールや電話、コンビニエンスストアでの証明書の発行などの利用が一時的にできなくなるトラブルとなりました。
住民票の変更などの手続きなどを行う窓口には、困惑した様子で受付に並ぶ利用者もいました。市によりますと、パソコンなどをつなげるLANケーブルを誤って接続し、大量の通信が発生したことが原因で、午前11時35分ごろに復旧したということです。
うるう年は4年に1回2月29日がある.他にも夏季オリンピックがあったり,四国八十八ヶ所巡りだと逆うち(88番から回る)があったりする.前回4年前の2020年はコロナ禍の入り口だったと思う.
そんな昔からある,うるう年だけど,珍しくシステム障害が相次いだ.スギ薬局の処方箋が出なくなったのと,神奈川,新潟,岡山,愛媛の4県警で免許更新ができなくなったシステム障害の原因が,うるう年の処理らしい.
私が新卒新人で就職した時,一番最初のCOBOLで作られているシステムでも日付判定処理はサブルーチン化され,うるう年判定は入っていた.土日も含めて営業日か否かを判定する的な処理で呼び出すようになったいたけど,先輩がうるう年の計算方法は教えてくれたのを覚えている. サブルーチン化しているから知らなくて良いけど知っておくのは常識という感じだった.
トラブルが発生した県警の免許更新システムは同一行者によって3年以内に導入されたものだそうで,今回が初めてのうるう年だった模様.テスト不足なんだけど,継承がないので若い人たちだけで作ってるのかな?と思ったりします.普通にカレンダー処理ってあると思うし.
そして重要なのは仕様上で「1年後の日付」を決めることです.2月28日にするのか3月1日にするのか.これは各システム毎に考え方が異なる部分.
また,興味深かったのは今回4県警でシステム障害が起こったけど,現在は各都道府県でシステムは個別の導入されているそう.そしてこれが新しく全国統一化される予定もある模様.そうなったら逆に何か障害あったら全国一斉だと懸念を出す人もいるけど,それはそういうものだろう.
そんな昔からある,うるう年だけど,珍しくシステム障害が相次いだ.スギ薬局の処方箋が出なくなったのと,神奈川,新潟,岡山,愛媛の4県警で免許更新ができなくなったシステム障害の原因が,うるう年の処理らしい.
私が新卒新人で就職した時,一番最初のCOBOLで作られているシステムでも日付判定処理はサブルーチン化され,うるう年判定は入っていた.土日も含めて営業日か否かを判定する的な処理で呼び出すようになったいたけど,先輩がうるう年の計算方法は教えてくれたのを覚えている. サブルーチン化しているから知らなくて良いけど知っておくのは常識という感じだった.
トラブルが発生した県警の免許更新システムは同一行者によって3年以内に導入されたものだそうで,今回が初めてのうるう年だった模様.テスト不足なんだけど,継承がないので若い人たちだけで作ってるのかな?と思ったりします.普通にカレンダー処理ってあると思うし.
そして重要なのは仕様上で「1年後の日付」を決めることです.2月28日にするのか3月1日にするのか.これは各システム毎に考え方が異なる部分.
また,興味深かったのは今回4県警でシステム障害が起こったけど,現在は各都道府県でシステムは個別の導入されているそう.そしてこれが新しく全国統一化される予定もある模様.そうなったら逆に何か障害あったら全国一斉だと懸念を出す人もいるけど,それはそういうものだろう.
バグは“数千パターンのテスト”をすり抜けた
―NTTデータ「2023/10/10 全銀ネット障害」について説明
https://gihyo.jp/article/2023/11/zengin-nttdata
すべてのフェーズでミスが重なった
―全銀ネットとNTTデータ、全銀システム通信障害の詳細を説明
https://gihyo.jp/article/2023/12/zengin-nttdata
引用: 800万円か.比べてはいけないけど事故対策の人件費より安い.
引用:
引用:
やっぱり規模が大きいから,「並行ラン」とか「去年のデータを一通り流す」とかを実現することは難しいか.
引用: そうなるよなぁ.
でも表面化した事故がこの程度で終えているのなら,やっぱりかなり優秀と言うことかな.
引用:
稼働して5分で不具合が出たのなら,すぐ前の状態に切り戻すロールバックがセオリーだと思うけど,複雑すぎて戻せないので対策前進しかなく,この全銀ネットの件で言えば,過去に失敗したことがないのでその部分の準備は足りなかったと言うことか.
自分がやるとした時にどこまでやれるだろう...
―NTTデータ「2023/10/10 全銀ネット障害」について説明
https://gihyo.jp/article/2023/11/zengin-nttdata
すべてのフェーズでミスが重なった
―全銀ネットとNTTデータ、全銀システム通信障害の詳細を説明
https://gihyo.jp/article/2023/12/zengin-nttdata
引用:
この2日間の障害発生において、当日中に処理が終わらなかった取引件数は全体で約566万件、うち全銀システムが補償対応を実施した件数は約8,000件、金額にして約800万円と公表されています。
引用:
「単体テストはほぼカバーできていたが、変更を加えていないテーブルが、ほかのプログラムが動いている状態でどのように動作するのか、その検証が不足していた」
引用:
結合試験や総合試験でほかのプログラムが多重で動いている環境(より本番に近い環境)でテストをしていれば、今回の破損は検出できていたはず。
やっぱり規模が大きいから,「並行ラン」とか「去年のデータを一通り流す」とかを実現することは難しいか.
引用:
たとえば“直近の最繁忙日の1日分のデータ”といった商用データを使ってカバーしていくほうが良いと考えている」と語っており、今後は実取引相当のデータを活用した疎通試験を実施していく意向を示しています。
でも表面化した事故がこの程度で終えているのなら,やっぱりかなり優秀と言うことかな.
引用:
NTTデータ側は復旧対応が遅れてしまった理由として以下を挙げています。
・復旧に向けた優先順位の考え方について、あらかじめ全銀ネットと合意していなかった
・見積もり精度よりスピード優先で対処し、限られた時間でのフィージビリティ(実現性)検証のまま前進した
・並走タスクの優先順位の考え方、代替案への切り替え時限の取り決めなく作業を実施した
稼働して5分で不具合が出たのなら,すぐ前の状態に切り戻すロールバックがセオリーだと思うけど,複雑すぎて戻せないので対策前進しかなく,この全銀ネットの件で言えば,過去に失敗したことがないのでその部分の準備は足りなかったと言うことか.
自分がやるとした時にどこまでやれるだろう...
Googleがなりすましに厳格になってSPFとかDMARCの設定がないと...
高校入試の出願システム、Gmailにメール届かず……神奈川県、受験生に「@gmail.com以外のアドレス使って」
https://www.itmedia.co.jp/news/articles/2401/16/news092.html
とみんな思っていたら,単純にひどいDNS設定ミスだったというオチ.
高校入試の出願システム、Gmailにメール届かず……神奈川県、受験生に「@gmail.com以外のアドレス使って」
https://www.itmedia.co.jp/news/articles/2401/16/news092.html
とみんな思っていたら,単純にひどいDNS設定ミスだったというオチ.
どういうこと?
プログラムミスで容量不足 全銀システム障害
https://nordot.app/1086652748626149745
引用:
MirosoftのAIで調べてみた.
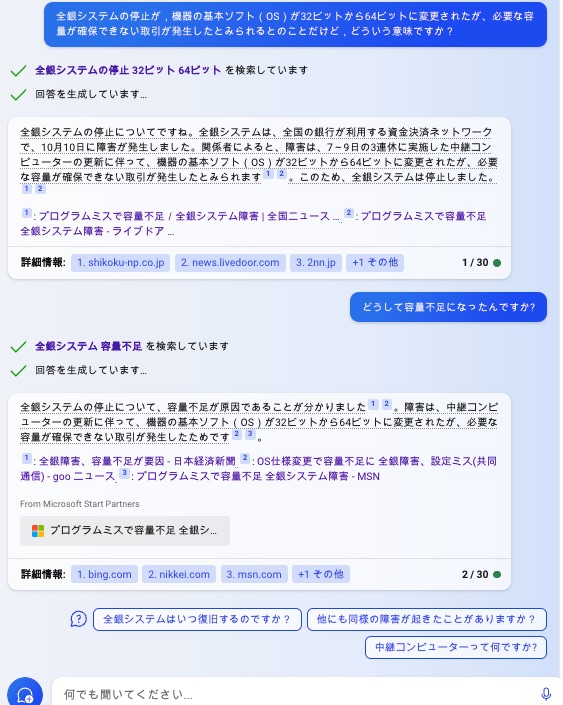
引用:
どういうこと?
もう1回問い合わせ.
引用: なるほど.わかった感じ.
プログラムミスで容量不足 全銀システム障害
https://nordot.app/1086652748626149745
引用:
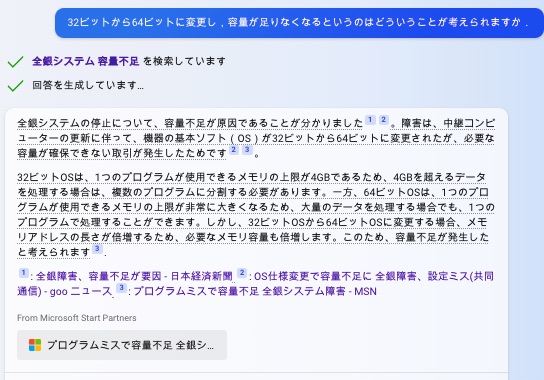
機器の基本ソフト(OS)が32ビットから64ビットに変更されたが、必要な容量が確保できない取引が発生したとみられる。
MirosoftのAIで調べてみた.
引用:
全銀システムの停止についてですね。全銀システムは、全国の銀行が利用する資金決済ネットワークで、10月10日に障害が発生しました。関係者によると、障害は、7~9日の3連休に実施した中継コンピューターの更新に伴って、機器の基本ソフト(OS)が32ビットから64ビットに変更されたが、必要な容量が確保できない取引が発生したとみられます12。このため、全銀システムは停止しました。
どういうこと?
もう1回問い合わせ.
引用:
32ビットから64ビットに変更し,容量が足りなくなるというのはどういうことが考えられますか.
全銀システムの停止について、容量不足が原因であることが分かりました12。障害は、中継コンピューターの更新に伴って、機器の基本ソフト(OS)が32ビットから64ビットに変更されたが、必要な容量が確保できない取引が発生したためです23。
32ビットOSは、1つのプログラムが使用できるメモリの上限が4GBであるため、4GBを超えるデータを処理する場合は、複数のプログラムに分割する必要があります。一方、64ビットOSは、1つのプログラムが使用できるメモリの上限が非常に大きくなるため、大量のデータを処理する場合でも、1つのプログラムで処理することができます。しかし、32ビットOSから64ビットOSに変更する場合、メモリアドレスの長さが倍増するため、必要なメモリ容量も倍増します。このため、容量不足が発生したと考えられます3.
Hotmail email delivery fails after Microsoft misconfigures DNS
https://www.bleepingcomputer.com/news/microsoft/hotmail-email-delivery-fails-after-microsoft-misconfigures-dns/
引用:
送信失敗するとこう言うエラーが出る模様.
引用:
所有歴25年近い自分のhotmailのアカウントは,Microsoft Storeからのメール受信しかこないから影響ないけどね.hotmailの利用者って,今どのくらいいるのだろうね.
https://www.bleepingcomputer.com/news/microsoft/hotmail-email-delivery-fails-after-microsoft-misconfigures-dns/
引用:
マイクロソフトがドメインのDNS SPFレコードを誤って設定したため、世界中のHotmailユーザーが、スパムとしてフラグを立てられたり、メッセージが届かないなど、メール送信に問題を抱えている。
送信失敗するとこう言うエラーが出る模様.
引用:
"For Email Administrators
This error is related to the Sender Policy Framework (SPF). The destination email system's evaluation of the SPF record for the message resulted in an error. Please work with your domain registrar to ensure your SPF records are correctly configured.
exhprdmxe26 gave this error:
Message rejected due to SPF policy - Please check policy for hotmail.com"
「メール管理者の方へ
このエラーは、送信者ポリシーフレームワーク(SPF)に関連しています。送信先のメールシステムがメッセージのSPFレコードを評価した結果、エラーが発生しました。ドメイン登録業者と協力して、SPFレコードが正しく設定されていることを確認してください。
exhprdmxe26はこのエラーを発生させました:
メッセージはSPFポリシーのため拒否されました - hotmail.comのポリシーを確認してください"
所有歴25年近い自分のhotmailのアカウントは,Microsoft Storeからのメール受信しかこないから影響ないけどね.hotmailの利用者って,今どのくらいいるのだろうね.
手順書が間違っていたのであって,作業ミスではないということかな?
モバイルSuica障害、電源工事ミスが原因 マニュアルに誤り、システムサーバへの電源供給切れる JR東
https://www.itmedia.co.jp/news/articles/2306/27/news079.html
引用:
でも
引用: 作業スタッフに誤りに気づいて欲しかったの体裁かなぁ.一般的に作業スタッフの多くは協力会社スタッフとか若手だろうに.
モバイルSuica障害、電源工事ミスが原因 マニュアルに誤り、システムサーバへの電源供給切れる JR東
https://www.itmedia.co.jp/news/articles/2306/27/news079.html
引用:
JR東日本は6月26日、24日に発生した、モバイルSuicaでのチャージなどができなくなった障害について、電源工事のミスが原因だったと発表した。工事マニュアルに間違いがあり、計画と異なるブレーカーを切ってしまったことで、システムサーバへの電源供給が止まってしまったという。
でも
引用:
作業スタッフがこの誤りに気づかず、「盤NO4(CV4)」のブレーカーを切ったため、夜間処理中のシステムへの電源供給が止まり、ハード故障やデータ不整合が発生した。
デジタル庁の大臣が謝罪までしたシステム障害.
川崎市様における証明書誤交付ついて(お詫び) - 富士通Japan株式会社
https://www.fujitsu.com/jp/group/fjj/about/resources/news/topics/2023/0509.html
引用: 単純に,負荷試験をしてないのかな?
「Fujitsu MICJET コンビニ交付」における新たな印刷障害について - 富士通Japan株式会社
https://www.fujitsu.com/jp/group/fjj/about/resources/news/topics/2023/0501.html
引用:
オンライントランザクション処理で「1秒」という時間がユニークにならないようにする事なんて普通にあると思うけどなぁ.
川崎市様における証明書誤交付ついて(お詫び) - 富士通Japan株式会社
https://www.fujitsu.com/jp/group/fjj/about/resources/news/topics/2023/0509.html
引用:
本事象の原因は、2か所のコンビニで、2名の住民の方が同一タイミング(時間間隔1秒以内)で証明書の交付申請を行った際に、後続の処理が先行する処理を上書きしてしまうことによるものです。本事象の原因となった当該プログラムの不具合は、既に修正および入れ替えを完了しております。なお、当該プログラムは川崎市様以外では使用されておりません。
「Fujitsu MICJET コンビニ交付」における新たな印刷障害について - 富士通Japan株式会社
https://www.fujitsu.com/jp/group/fjj/about/resources/news/topics/2023/0501.html
引用:
1月4日(水)システム稼働以降
1月17日、3月22日、4月18日、地方公共団体情報システム機構様からエラーを検知した旨の連絡が当該自治体様にあり、エラーの確認依頼を受けました。確認結果として、エラーの後、再度申請が行われ、印刷が正常に終了していることを回答しました。
4月21日(金)
先日発生した当該サービスの印刷障害に対する再発防止策の一環として、類似サービスの総点検を行っていたところ、同日23時頃に当該自治体様のシステム環境において、申請者とは異なる住民の方の証明書が発行される可能性のあるプログラムを検知しました。
4月22日(土)
10時に当該自治体様へ本件に関する報告を行い、同日のシステム運用時間終了後に当該プログラムの一部修正および入れ替えを実施しました。
4月23日(日)~ 26日(水)
印刷障害の発生有無について調査を開始しました。その後、不具合事象(誤交付)につながる可能性のあるエラーログを3件(発生日:1月17日、3月22日、4月18日)検知しました。
4月27日(木)
当該自治体様に対し、システムログに基づいて影響を受けた可能性のある住民の方、証明書の種類などの調査状況を報告しました。
4月28日(金)
当該自治体様が可能性のある住民の方に確認を行った結果、2件の証明書誤交付が発生していたことが判明しました。
オンライントランザクション処理で「1秒」という時間がユニークにならないようにする事なんて普通にあると思うけどなぁ.
一般ニュースにも出てた大規模障害のようだけれど,実感が無くて.
NTT東西の「フレッツ光」大規模障害、原因は特定のサーバから届いた“特殊なパケット”だった
https://www.itmedia.co.jp/news/articles/2304/03/news168.html
引用:
根本原因が取り除かれてないのなら,同じ障害が発生しますね.この手の自動フェイルオーバーで両系ダウンというのは,よく報道されるパターン.逆にいうと,長時間影響が出るほどのレアケースってことかな.機器故障なんて,NTTレベルだったら日々起きているだろうし.
気になるのはこの部分.
引用:
やっぱり海外製だと対応が遅れるんじゃなかろうか,とか思っちゃうけどな.
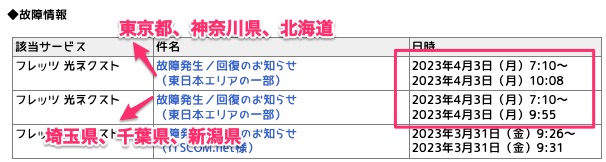
うちで使っている「フレッツ光ネクスト」だと,朝7時10分から朝10時8分くらいまで障害が発生していたようだけれど,その時間に使って無かったので自分の実害がわからない.
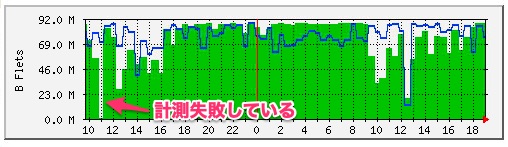
30分に一度のスピードテストの結果を見ると,11時ごろに凹んでいるのだけれど,これは時間的には違うし,影響が出たかどうかはわからないな.
NTT東西の「フレッツ光」大規模障害、原因は特定のサーバから届いた“特殊なパケット”だった
https://www.itmedia.co.jp/news/articles/2304/03/news168.html
引用:
障害が発生したのは午前7時10分ごろ。複数のNTT局舎内にある加入者収容装置が特殊なパケットを受信後にリブートした。フェイルオーバー機能が働き、自動的に別の装置に切り替わったものの、そちらも同じ障害が発生した。
根本原因が取り除かれてないのなら,同じ障害が発生しますね.この手の自動フェイルオーバーで両系ダウンというのは,よく報道されるパターン.逆にいうと,長時間影響が出るほどのレアケースってことかな.機器故障なんて,NTTレベルだったら日々起きているだろうし.
気になるのはこの部分.
引用:
障害を起こした加入者装置は、全て同じ海外メーカー製の新製品だった。とはいえ以前から使用してきた製品の後継機で、両社とも2018年から順次導入している「ある程度こなれているもの」だった。
やっぱり海外製だと対応が遅れるんじゃなかろうか,とか思っちゃうけどな.
うちで使っている「フレッツ光ネクスト」だと,朝7時10分から朝10時8分くらいまで障害が発生していたようだけれど,その時間に使って無かったので自分の実害がわからない.
30分に一度のスピードテストの結果を見ると,11時ごろに凹んでいるのだけれど,これは時間的には違うし,影響が出たかどうかはわからないな.
1週間丸ごと全く使えない,というわけでもないのだろうけれど,復旧したと宣言するまでに1週間かかるクラウドサービスって,クリティカルな業務では使えない,という感じだろうね.
KDDIのクラウド障害、今度は約1週間で復旧 一部で仮想サーバ作成できず、原因は?
https://www.itmedia.co.jp/news/articles/2303/23/news170.html
引用:
KDDIのクラウド障害、今度は約1週間で復旧 一部で仮想サーバ作成できず、原因は?
https://www.itmedia.co.jp/news/articles/2303/23/news170.html
引用:
KDDIは3月22日、15日から障害が発生していたクラウドサービス「KDDIクラウドプラットフォームサービス」(KCPS)が復旧したと発表した。
Apple Mailに設定してあるhotmailのアカウントで急にパスワード認証を求めるダイアログが出てきて,何度パスワードを投入しても認証されないので障害に気付きました.
「Microsoft 365」サービスに障害発生 ~TeamsやOutlookなどにアクセス不可に
https://forest.watch.impress.co.jp/docs/news/1473149.html
引用:
障害が発生しているとされるサービスにはhotmailは無いけれど,いつの間にか事実上終了しているらしく,outlook.comというサービスになっている模様.
追記2023/02/02
こんな情報が.
マイクロソフト、1月25日に発生した大規模障害の原因を説明
https://japan.zdnet.com/article/35199351/
引用:
予定されていたとはいえ,日本時間午後4時5分って,日本だと業務終了前の追い込みの時間帯だから,営業日報とか書こうとしている人の被害多数かも?
引用:
ネットワーク機器の切り替えで,伝播に時間がかかって障害発覚までに時間がかかって復旧にも時間がかかるというようなことって,よくありますね.KDDIの障害とかもそういうやつだったな.
KDDI通信障害 (2022年)
https://ja.wikipedia.org/wiki/KDDI%E9%80%9A%E4%BF%A1%E9%9A%9C%E5%AE%B3_(2022%E5%B9%B4)
引用:
で,KDDIを調べていたら...
KDDIのクラウド障害、完全復旧には2週間以上かかる可能性【訂正あり】
https://www.itmedia.co.jp/news/articles/2301/31/news149.html
引用:
「Microsoft 365」サービスに障害発生 ~TeamsやOutlookなどにアクセス不可に
https://forest.watch.impress.co.jp/docs/news/1473149.html
引用:
【1月25日17時20分追記】 Microsoftによると、下記のサービスがアクセスできなくなっているとのこと。現在、ネットワークに関する潜在的な問題を特定したとしている。
Microsoft Teams
Exchange Online
Outlook
SharePoint Online
OneDrive for Business
Microsoft Graph
障害が発生しているとされるサービスにはhotmailは無いけれど,いつの間にか事実上終了しているらしく,outlook.comというサービスになっている模様.
追記2023/02/02
こんな情報が.
マイクロソフト、1月25日に発生した大規模障害の原因を説明
https://japan.zdnet.com/article/35199351/
引用:
Microsoftは、今回の障害が発生する前に、協定世界時間1月25日午前7時5分(日本時間午後4時5分)から予定されていたアップデートに伴い、Azureのパブリッククラウド、Microsoft 365、Power BIのAzureリソースに接続する際に遅延やタイムアウトが発生する可能性があると予告していた。ところが、欧州で仕事が始まる頃には、アップデートの影響は遅延だけでは済まなくなり、WAN全体のネットワークデバイスに影響を与え始めた。これによって、データセンターでサービス間の接続が切断されるとともに、同社の顧客がデータセンター間でデータを転送するためのプライベートネットワークである「ExpressRoute」の接続も遮断された。
予定されていたとはいえ,日本時間午後4時5分って,日本だと業務終了前の追い込みの時間帯だから,営業日報とか書こうとしている人の被害多数かも?
引用:
レポートでは、原因について「WANルーターのIPアドレスを更新するために計画された変更の一環としてルーターに与えられた特定のコマンドをきっかけとして、そのルーターがWAN内の他のすべてのルーターにメッセージを送信した。
ネットワーク機器の切り替えで,伝播に時間がかかって障害発覚までに時間がかかって復旧にも時間がかかるというようなことって,よくありますね.KDDIの障害とかもそういうやつだったな.
KDDI通信障害 (2022年)
https://ja.wikipedia.org/wiki/KDDI%E9%80%9A%E4%BF%A1%E9%9A%9C%E5%AE%B3_(2022%E5%B9%B4)
引用:
ルーターの交換中に不具合が発生し、切り戻し中にデータ不整合が発生。
で,KDDIを調べていたら...
KDDIのクラウド障害、完全復旧には2週間以上かかる可能性【訂正あり】
https://www.itmedia.co.jp/news/articles/2301/31/news149.html
引用:
1月28日午前4時ごろから約80時間にわたって障害が発生しているKDDIのクラウドサービス「KDDI クラウドプラットフォームサービス」。同社は31日、完全復旧に2週間以上かかる可能性があると明らかにした。
セブンでチケット発行できない日のライブに,あらかじめ発券しておいたので大丈夫だった件.
セブン-イレブン、チケット発券できない不具合から復旧 原因は「データ切り替えが正常に作動せず」
https://www.itmedia.co.jp/news/articles/2209/24/news048.html
まぁ,ファミマで発券だったんだけど.最近はアプリを見せるチケットレスもあるけれど,アプリが起動しないとか会場で通信混雑とかもあると思うので,スクショは取っておく用心はしているが,有効期限が10分とかの短いQRコードをだだせるやつはシステムに任せるしかないな.
セブン-イレブン、チケット発券できない不具合から復旧 原因は「データ切り替えが正常に作動せず」
https://www.itmedia.co.jp/news/articles/2209/24/news048.html
まぁ,ファミマで発券だったんだけど.最近はアプリを見せるチケットレスもあるけれど,アプリが起動しないとか会場で通信混雑とかもあると思うので,スクショは取っておく用心はしているが,有効期限が10分とかの短いQRコードをだだせるやつはシステムに任せるしかないな.
2013年の出来事に対する裁判か.10年近くになるのね.
ソフトバンクに108億円賠償命令 郵政インフラ更新遅延で―東京地裁
https://www.jiji.com/jc/article?k=2022090901279
引用: ソフトバンクテレコムが入札で通信回線を勝ち取ったけど,田舎のラスト1マイルが繋がらないなんてことを言っていた人がいた. 全国津々浦々,田舎の郵便局にも網羅的に回線を引っ張らなければいけないけれど,その当時,回線が郵便局近くになくて,さらに1,2年は工事予定が無いなんて言ってたけど,そういうのどうするんだろうね,って話.無線で飛ばすにも許可申請などが煩雑で時間が掛かるなんて.
ソフトバンクに108億円賠償命令 郵政インフラ更新遅延で―東京地裁
https://www.jiji.com/jc/article?k=2022090901279
引用:
日本郵政グループの通信インフラ更新が期日までに終わらず損害を受けたとして、郵政子会社が発注先のソフトバンクと野村総合研究所に約161億円の損害賠償を求めた訴訟の判決が9日、東京地裁であった。和波宏典裁判長(篠田賢治裁判長代読)はソフトバンクに約108億5400万円の賠償を命じた。
最近の新興勢力なのかな? 焼肉きんぐ.うちのまぁまぁ近くにも5年前にデニーズの跡にできていたのだけれど,そこでこんな事故が.
14万件の個人情報を誤削除、復旧できず 「焼肉きんぐ」運営元がサーバ移行でミス
https://www.itmedia.co.jp/news/articles/2209/05/news161.html
引用:
これで思い出したのがバックアップ見つかるとして記事にした「ふくいナビ」があったけれど,無かったはずのバックアップが出てくる恐怖よりは,もうありませんと言い切った今回の対応の方が好感度が高い模様.
6月末に移行して8月5日にわかったということは,7月末ごろに8月誕生日キャンペーンメールの配信手続きしようとしたらデータがなかったので調べて経緯がわかった,という感じかな.
どうすればよかったのか? 移行前のフルデータを手元の納品させておけばよかったのかな.それはそれで手順とか保存方式とか,コストもかかるが情報の獲得コストよりは安いはず.
14万件の個人情報を誤削除、復旧できず 「焼肉きんぐ」運営元がサーバ移行でミス
https://www.itmedia.co.jp/news/articles/2209/05/news161.html
引用:
飲食チェーン「焼肉きんぐ」などを運営する物語コーポレーション(愛知県豊橋市)は9月5日、顧客の個人情報14万3876件を誤って削除し、復旧できない状態だと発表した。サーバ移行時の確認不足によりデータを移行し損ね、そのまま古いサーバの契約期間が終了したという。削除した情報の漏えいは確認していない。
これで思い出したのがバックアップ見つかるとして記事にした「ふくいナビ」があったけれど,無かったはずのバックアップが出てくる恐怖よりは,もうありませんと言い切った今回の対応の方が好感度が高い模様.
6月末に移行して8月5日にわかったということは,7月末ごろに8月誕生日キャンペーンメールの配信手続きしようとしたらデータがなかったので調べて経緯がわかった,という感じかな.
どうすればよかったのか? 移行前のフルデータを手元の納品させておけばよかったのかな.それはそれで手順とか保存方式とか,コストもかかるが情報の獲得コストよりは安いはず.
一般のテレビニュースでもシステム障害というか「職場の人と連絡つかない」の流れでケータイ電話の通信障害風に報道されている気がする.
「Microsoft Teams」の障害、原因はストレージサービスへの接続不良
https://japan.zdnet.com/article/35190804/
大企業は「Microsoft Teams」「LINE WORKS」が上位、小企業では「Chatwork」「Slack」などが拮抗
https://internet.watch.impress.co.jp/docs/news/1414371.html
引用: Slack,Chatworkが多いのかと思ったけれど,これはスタートアップで利用されがちってことかなぁ.1000人規模の大企業だとMicrosoft 365を契約してそのまま追加料金なしで使えるからTeamsが多いのだろうなぁ.
障害に備えて第2の連絡手段を持っておく必要があるとされていたけど,代替というかTeamsでシステムトラブルですという連絡をFAXで送っている姿がテレビで出てた.又は「仕事にならない」からの「仕事できないのでトラブル長引けばいいのに」的なコメントもあって,意外と和やかな感じが・・・
「Microsoft Teams」の障害、原因はストレージサービスへの接続不良
https://japan.zdnet.com/article/35190804/
大企業は「Microsoft Teams」「LINE WORKS」が上位、小企業では「Chatwork」「Slack」などが拮抗
https://internet.watch.impress.co.jp/docs/news/1414371.html
引用:
従業員数1000名以上の会社のツール別利用率ランキング(n=663)では、Microsoft Teamsが21.4%、LINE WORKSが10.3%、Workplaceが4.0%、Slackが3.7%、Chatworkが2.8%、Talknoteが0.4%、directが0.3%の順。
障害に備えて第2の連絡手段を持っておく必要があるとされていたけど,代替というかTeamsでシステムトラブルですという連絡をFAXで送っている姿がテレビで出てた.又は「仕事にならない」からの「仕事できないのでトラブル長引けばいいのに」的なコメントもあって,意外と和やかな感じが・・・
KDDIの方が大きかったから,テレビニュース的には話題にならなかったな.
1週間続いた立川市の通信システム障害が復旧、原因はいまだ調査中
https://xtech.nikkei.com/atcl/nxt/news/18/13240/
引用: 最小限で継続できるシステムを切り分けて続行する現場判断が重要だなぁ.
1週間続いた立川市の通信システム障害が復旧、原因はいまだ調査中
https://xtech.nikkei.com/atcl/nxt/news/18/13240/
引用:
同市役所では障害発生後、窓口業務など市民サービスを優先し、システムの機能や性能を部分的に停止させた状態で稼働を維持する縮退運用を続けていた。2022年7月3日夜にネットワーク機器の交換などを実施し、復旧に至った。同月4日および5日午前9時30分時点では、通常通り業務ができているという。
長期間広範囲に影響が出ているので,直接影響を受けてないので客観的に感慨深い.
・携帯通話できない
・固定電話も通話できない
・待ち合わせができない
・電子チケットが使えない
・緊急電話をかけられない
・山で遭難してるが電話をかけられない
・回復の際にデータ通信が通話より優先された
・輻輳を抑えるために50%の通信制限
・気象庁のアメダスデータが連携されない
・ヤマト運輸のPUDOの受け取りができない
・バス運行の走行位置,到着時間予測システムが利用できない
・コロナで自宅療養中の120人から130人と連絡が取れない
・auショップに行列
・au回線利用の銀行ATMが利用できない
障害の発生契機は,VoLTE交換機のメンテナンスでトラフィックのルート変更の実施の模様.KDDIは3G回線を3月末で終えているので,より影響が大きいのかな.
KDDIの高橋誠社長が記者会見で単独で色々な質問に答えていたのが好印象とのこと.東証アローズの障害の時も同じように明確に答えている担当役員の評判が良かった覚えがあるな.
・携帯通話できない
・固定電話も通話できない
・待ち合わせができない
・電子チケットが使えない
・緊急電話をかけられない
・山で遭難してるが電話をかけられない
・回復の際にデータ通信が通話より優先された
・輻輳を抑えるために50%の通信制限
・気象庁のアメダスデータが連携されない
・ヤマト運輸のPUDOの受け取りができない
・バス運行の走行位置,到着時間予測システムが利用できない
・コロナで自宅療養中の120人から130人と連絡が取れない
・auショップに行列
・au回線利用の銀行ATMが利用できない
障害の発生契機は,VoLTE交換機のメンテナンスでトラフィックのルート変更の実施の模様.KDDIは3G回線を3月末で終えているので,より影響が大きいのかな.
KDDIの高橋誠社長が記者会見で単独で色々な質問に答えていたのが好印象とのこと.東証アローズの障害の時も同じように明確に答えている担当役員の評判が良かった覚えがあるな.
バックアップ設計していても容量計算ミスで運用できないから一時停止している最中の作業ミスによる消失かな.
・やっているつもり
・やってもらっているつもり
確認不足か.
自治体向けSaaSでデータ消失、最大257団体に影響 - 同期操作のミスで
https://www.security-next.com/137003/
引用:
・やっているつもり
・やってもらっているつもり
確認不足か.
自治体向けSaaSでデータ消失、最大257団体に影響 - 同期操作のミスで
https://www.security-next.com/137003/
引用:
しかし実際は、データベースサーバにおいて日次バックアップを取得していたものの、ファイル保管サーバに関しては、サーバ容量を考慮して日次バックアップを一時停止していたという。停止していた期間についてはコメントを避けた。
まだ今現在進行中だけれど,興味深い.
Oracle Cloudアカウントが突然停止した!
https://zenn.dev/shinshin86/scraps/022e44712274fd
引用: 初期の問い合わせも四苦八苦しているので,こう言うのはやっぱり日本法人で担当営業のケータイ番号を何人か知っているくらいの会社じゃないと任せづらいかな,なんて思った.
ユーチューバ的な人も警告なくアカウントがバンされたというニュースも度々聞くよね.
Oracle Cloudアカウントが突然停止した!
https://zenn.dev/shinshin86/scraps/022e44712274fd
引用:
Oracle Cloud上でサーバプログラムを稼働させているのだが、そちらが止まってしまっていることから気づいた。
もしかしたら自分に何かしらの落ち度があったのかもしれないが、それも含め、ひとまずOracle Cloudアカウントが一時停止した原因や、実際に自分が取った対応はこちらにまとめておこうと思う。
(一応自分としては今のところ心当たりはなく、問題なくアカウントの運用ができていると思っていたので、発覚した際はかなり驚いた)
ユーチューバ的な人も警告なくアカウントがバンされたというニュースも度々聞くよね.
アトラシアンのJIRAでシステム障害によりデータを
一部のお客様へ影響しているアトラシアンサービスの停止について
https://www.atlassian.com/ja/blog/april-2022-outage-update
引用: コミュニケーションギャップとスクリプトの不具合の2件が原因だと分析.「恒久的にデータ削除」とあるので物理削除を実行したということか.
バックアップは30日分あるというので対象が400社と多いけれど戻すことはできるってことかなぁ.
クラウドサービスのバックアップは業者を信じるしかない点.これを許せるか否かのポリシーは先に決めておく必要があるかな.といつも思う.
一部のお客様へ影響しているアトラシアンサービスの停止について
https://www.atlassian.com/ja/blog/april-2022-outage-update
引用:
4月4日(月) 20:12 UTC頃、アトラシアンクラウドをご利用の約400社のお客様が、アトラシアン製品全体を通してサービスの停止を経験されました。当社は現在、当該サイトの復旧作業を進めており、サービス停止の影響を受けたユーザーの45%程度にまで機能の復旧が完了しています。すべてのお客様に対するサービス復旧は、今後2週間以内を見込んでおります。
バックアップは30日分あるというので対象が400社と多いけれど戻すことはできるってことかなぁ.
クラウドサービスのバックアップは業者を信じるしかない点.これを許せるか否かのポリシーは先に決めておく必要があるかな.といつも思う.
こんな情報.
地銀などシステム障害9行すべてでほぼ復旧 ATMなど利用可能に 2022年3月27日 18時11分
https://www3.nhk.or.jp/news/html/20220327/k10013553961000.html
引用: ローソンはIBMのパッケージとは別の別のシステムだけれど,データセンタの障害なので巻き込まれた模様.
運営していたのはキンドリルジャパン.IBMのインフラ会社として2021年7月に分社化しました.
日本IBMのデータセンター障害、通常電源切り替えまで丸5日 - 2021.07.05
https://active.nikkeibp.co.jp/atcl/act/19/00012/070500509/
引用:
日本IBMの幕張データセンターでシステム障害、電源故障で発煙 - 2021.06.25
https://xtech.nikkei.com/atcl/nxt/news/18/10693/
引用:
電源故障で電力供給が4分間停止、日本IBMのデータセンター障害 2020.02.25
https://xtech.nikkei.com/atcl/nxt/news/18/07145/
引用:
IBMはここ数年で電源障害によるトラブルを頻発させていると思うけれど,影響を受けている銀行が異なるので,それぞれ別のデータセンタのようですね.
色々と買い取って運営しているのだろうか? ノウハウの横展開とかそういうのないのかなぁ.
停電でデータセンタが停止すると2006年8月14日首都圏停電を思い出す.予備電源が稼働しなかったデータセンタがあって被害を受けたw
その後,そのデータセンタは頻繁に定期的に電源切替テストしているけどね.人間も入れ替えるから頻繁な訓練は大事.
それと,意外と定期的に怒っている停電.昨日もうちの近くの街が2時間ほど停止していた模様.原因不明ということが分かったみたいだが.
https://teideninfo.tepco.co.jp/flash/13000000000.html
2022/03/31追記
この情報と関連したりするのだろうか.どうなんだろう.APCの問題だと使ってそうだし.
米国当局、UPSをインターネットから外すよう呼びかけ
https://news.mynavi.jp/techplus/article/20220330-2307631/
地銀などシステム障害9行すべてでほぼ復旧 ATMなど利用可能に 2022年3月27日 18時11分
https://www3.nhk.or.jp/news/html/20220327/k10013553961000.html
引用:
地方銀行など9つの銀行では26日からシステム障害のためATM=現金自動預け払い機やインターネットバンキングが使えなくなっていましたが、すべての銀行で27日午前までにシステムが復旧し、ATMは朝から使えるようになっています。
26日午前からシステム障害が起きたのは▽水戸市に本店がある常陽銀行、▽宇都宮市に本店がある足利銀行、▽岐阜市に本店がある十六銀行、▽奈良市に本店がある南都銀行、山口フィナンシャルグループ傘下の▽広島市に本店があるもみじ銀行、▽下関市に本店がある山口銀行、▽北九州市に本店がある北九州銀行そして、▽高松市に本店がある百十四銀行、それに▽ローソン銀行の9つの銀行です。
運営していたのはキンドリルジャパン.IBMのインフラ会社として2021年7月に分社化しました.
日本IBMのデータセンター障害、通常電源切り替えまで丸5日 - 2021.07.05
https://active.nikkeibp.co.jp/atcl/act/19/00012/070500509/
引用:
日本IBMは2021年7月2日までに、幕張データセンター(千葉市美浜区)で起きた電源障害に関し、6月30日未明に通常電源からの配電に切り替えたと明らかにした。保守用電源に切り替えてから通常電源に戻すまで丸5日を要した。
日本IBMの幕張データセンターでシステム障害、電源故障で発煙 - 2021.06.25
https://xtech.nikkei.com/atcl/nxt/news/18/10693/
引用:
日本IBMは2021年6月25日、同社のデータセンターでシステム障害が発生し、顧客のシステムに影響が出ていると明らかにした。電源系統の一部が故障し、発煙があった。大半のシステムは復旧したが、一部顧客のシステムで復旧作業を続けており、25日午後6時10分時点で全面復旧に至っていない。
電源故障で電力供給が4分間停止、日本IBMのデータセンター障害 2020.02.25
https://xtech.nikkei.com/atcl/nxt/news/18/07145/
引用:
住信SBIネット銀行は7時間以上にわたって、振り込みや残高照会などほぼすべての取引ができなくなった。八十二銀行や筑波銀行、武蔵野銀行といった複数の地方銀行でもATMやインターネットバンキングなどを通じた取引ができなくなった
IBMはここ数年で電源障害によるトラブルを頻発させていると思うけれど,影響を受けている銀行が異なるので,それぞれ別のデータセンタのようですね.
色々と買い取って運営しているのだろうか? ノウハウの横展開とかそういうのないのかなぁ.
停電でデータセンタが停止すると2006年8月14日首都圏停電を思い出す.予備電源が稼働しなかったデータセンタがあって被害を受けたw
その後,そのデータセンタは頻繁に定期的に電源切替テストしているけどね.人間も入れ替えるから頻繁な訓練は大事.
それと,意外と定期的に怒っている停電.昨日もうちの近くの街が2時間ほど停止していた模様.原因不明ということが分かったみたいだが.
https://teideninfo.tepco.co.jp/flash/13000000000.html
2022/03/31追記
この情報と関連したりするのだろうか.どうなんだろう.APCの問題だと使ってそうだし.
米国当局、UPSをインターネットから外すよう呼びかけ
https://news.mynavi.jp/techplus/article/20220330-2307631/
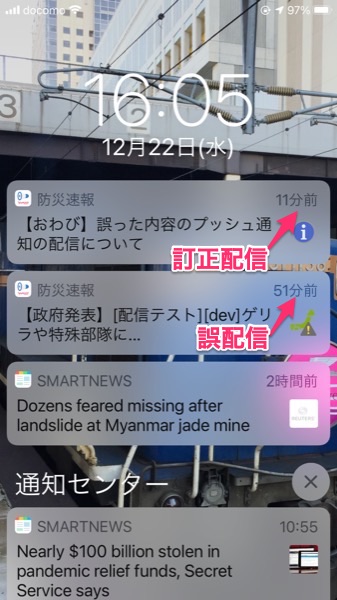
少し前の話題になるけれど
「ゲリラ、特殊部隊が攻撃」 ヤフーが防災速報誤配信
https://www.jiji.com/jc/article?k=2021122200956
引用:
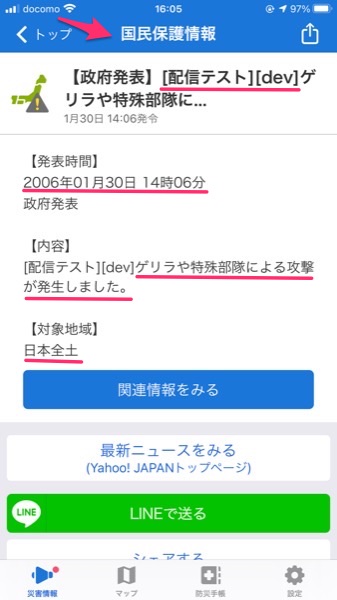
その内容というのがこれ.
ご配信に対するお詫びの通知までは,40分ほどなので速い方だろうとおもう.
今回どうすべきだったか?
市町村の防災放送は定期的に疎通・動作確認しているから,こういうアプリでもテストは重要.ただしそのテキストの内容が尋常では無いのが今回の問題.
テスト内容が不適切なのは,もう10年前だけど「セシウムさん騒動」があった.
でも地震速報ならまだしも,ゲリラや特殊部隊・・・の配信は,自動で配信でも無いだろうに.
「ゲリラ、特殊部隊が攻撃」 ヤフーが防災速報誤配信
https://www.jiji.com/jc/article?k=2021122200956
引用:
ゲリラや特殊部隊による攻撃が発生しました」というテスト用通知文が誤って配信されたと発表した。職員の人為的ミスで、配信予定のないダミーの文章が通知されてしまったという。
その内容というのがこれ.
ご配信に対するお詫びの通知までは,40分ほどなので速い方だろうとおもう.
今回どうすべきだったか?
市町村の防災放送は定期的に疎通・動作確認しているから,こういうアプリでもテストは重要.ただしそのテキストの内容が尋常では無いのが今回の問題.
テスト内容が不適切なのは,もう10年前だけど「セシウムさん騒動」があった.
でも地震速報ならまだしも,ゲリラや特殊部隊・・・の配信は,自動で配信でも無いだろうに.
停電で思わぬシャットダウンが行われた場合,サーバが壊れるのはよくある事.クラウドだから大丈夫なんてことは無いので,バックアップやリカバリプランはオンプレと同等に設計が必要だね.
運用が目の前にないので忘れがちだと思うけど.
AWSが停電でダウンし「一部のハードウェアがリカバリできない可能性」が通達される
https://gigazine.net/news/20211224-aws-power-failure/
引用:
運用が目の前にないので忘れがちだと思うけど.
AWSが停電でダウンし「一部のハードウェアがリカバリできない可能性」が通達される
https://gigazine.net/news/20211224-aws-power-failure/
引用:
AWSステータスレポートには以下のように「電力が落ちた場合によく起こることですが、一部のハードウェアが回復できない可能性や、影響のあったEC2インスタンスやEBSボリュームを完全に回復させたりできない可能性があります。現状ではまだ断言できませんが、リカバリ中である少数のEC2インスタンスやEBSボリューム全てを回復できることは難しいと考えています」と表示されていたとのこと。
有料になっちゃったので見れないのだけれど.
3メガバンクの「みずほ」だけシステム障害が頻発する理由
マルチベンダーとシングルベンダーの長所と短所
https://jbpress.ismedia.jp/articles/-/66788
システムがサービスインすると,そのプロマネやっていた人は出世して異動になったりする.外部のSIerのキーマンも離れていく.仕様策定していた人も徐々に離れていく.
新規構築システムへ長れ,運用は新しく外から人を集めて「定型処理を低コストに」という動きになる.
そういう現場は多いね.
以前勤めていた製鉄会社では,もうその筋何十年のベテランが,過去のノウハウだけで生きていて,すでにシステムエンジニアなのか?って状態だったけれど,新しいことに手出しもしないけれどシステムも安定運用させてた.
渡鳥的な人と生き字引的な人を振り分けるのが良いのかなぁ.と思ったりする.しかし複雑化しているから一人で全部できるもん!時代でもないし.
3メガバンクの「みずほ」だけシステム障害が頻発する理由
マルチベンダーとシングルベンダーの長所と短所
https://jbpress.ismedia.jp/articles/-/66788
システムがサービスインすると,そのプロマネやっていた人は出世して異動になったりする.外部のSIerのキーマンも離れていく.仕様策定していた人も徐々に離れていく.
新規構築システムへ長れ,運用は新しく外から人を集めて「定型処理を低コストに」という動きになる.
そういう現場は多いね.
以前勤めていた製鉄会社では,もうその筋何十年のベテランが,過去のノウハウだけで生きていて,すでにシステムエンジニアなのか?って状態だったけれど,新しいことに手出しもしないけれどシステムも安定運用させてた.
渡鳥的な人と生き字引的な人を振り分けるのが良いのかなぁ.と思ったりする.しかし複雑化しているから一人で全部できるもん!時代でもないし.
大規模長時間の障害でワイドショーから一般ニュースまで取り上げられていたドコモの通信障害.
都内だけれど都心では無いからか,通信障害の影響を全く受けなかった自宅警備員なので,文句は無いのだけれど.
ドコモの通信障害はなぜ長期化したのか? 障害の告知方法やMVNOの扱いには課題も
https://www.itmedia.co.jp/mobile/articles/2110/16/news031.html
引用: 1つ思うのは,通信キャリアは選挙期間中は工事をしないんじゃなかったかなーって.
IoT用って,たとえば自動販売機とかに入っているやつですかね? そこの問題が普通のデータ通信や音声通信にまで影響が出ているところも.以前はデータはダメでも音声回線は大丈夫なんてこともあったけど,VoLTEとかにして電波一緒にしているのかなぁ.
都内だけれど都心では無いからか,通信障害の影響を全く受けなかった自宅警備員なので,文句は無いのだけれど.
ドコモの通信障害はなぜ長期化したのか? 障害の告知方法やMVNOの扱いには課題も
https://www.itmedia.co.jp/mobile/articles/2110/16/news031.html
引用:
直接的なきっかけになったのは、14日0時に始まったIoTサービス用の加入者/位置情報サーバ(HSS/HLR)を切り替える作業だ。
IoT用って,たとえば自動販売機とかに入っているやつですかね? そこの問題が普通のデータ通信や音声通信にまで影響が出ているところも.以前はデータはダメでも音声回線は大丈夫なんてこともあったけど,VoLTEとかにして電波一緒にしているのかなぁ.
今年になってから,みずほ銀行の大規模システム障害が多発しているけれども.
みずほ、基幹システム「使いこなせていない」-障害多発で担当役員
https://www.bloomberg.co.jp/news/articles/2021-10-08/R0N0O5T1UM1501
引用: 1つ壊れて縮退運転中は,二重障害まではマッタナシ!状態なので,これは使いこなせてないという以前の問題の気がするな. でも1時間後の2つ目の故障は運が悪いというか,その運を引き寄せてしまったとしか言えないな..
みずほシステム障害、特定機器の故障率上昇気づかず 再発防止策公表
https://mainichi.jp/articles/20211008/k00/00m/020/309000c
引用:
ほう.
引用: ずっと同じ人が見守っていたら,明らかに気づくでしょう.故障交換対応の振り返りなんて毎月するでしょ? 予防保守で機器交換なんて普通にあるし.ネットベンチャーじゃないんだし,これは銀行だぜ?って感じ.
コンピュータシステムが高度化して複雑化,全体を把握できる人が少なくなる中,立ち上げ,構築,運用とフェーズが分業化.ITベンダに依存していて人事もコントロールできない.銀行内でもノウハウが希薄化しているのだろうな.
そして一番重要なのは「愛」の欠如.これが重要.担当者がシステムに対して愛を注ぎ込める体制の構築が経営者に必要なことだと思う.
いや,メインフレームの集中化してシンプルにすれば良いのでは?とおもったりする.護るべきところを局所化する.
「COBOLエンジニアがいない」なんていうのは幻想.簡単に量産できるよ.プログラム言語としては簡単なんだし.なんのためのその処理かがわからないのは,何を使って作っても一緒w
みずほ、基幹システム「使いこなせていない」-障害多発で担当役員
https://www.bloomberg.co.jp/news/articles/2021-10-08/R0N0O5T1UM1501
引用:
8月20日の障害については、サーバーにある1台目のハードディスクが故障した後、2台目のハードディスクが単独で作動したものの、約1時間後に故障。「極めてまれ」な二重障害が起きたと説明した。特定型番のハードディスクの故障率が昨年と比べて倍程度に上昇していたことも分かった
みずほシステム障害、特定機器の故障率上昇気づかず 再発防止策公表
https://mainichi.jp/articles/20211008/k00/00m/020/309000c
引用:
全店舗の窓口業務で取引ができなくなった8月20日の障害では、特定の型番の機器で故障率が上昇していたにもかかわらず、気付かずに障害につながっていたことが判明。復旧のため予備の機器に切り替える作業も、みずほやシステム会社による手順書が不十分だったため、復旧作業に手間取ったことが明らかになった。
ほう.
引用:
システム会社が解析調査をした結果、今回故障した機器と同じ型番の機器が今年に入って故障率が上昇していたが、事前に問題を把握できなかった。
コンピュータシステムが高度化して複雑化,全体を把握できる人が少なくなる中,立ち上げ,構築,運用とフェーズが分業化.ITベンダに依存していて人事もコントロールできない.銀行内でもノウハウが希薄化しているのだろうな.
そして一番重要なのは「愛」の欠如.これが重要.担当者がシステムに対して愛を注ぎ込める体制の構築が経営者に必要なことだと思う.
いや,メインフレームの集中化してシンプルにすれば良いのでは?とおもったりする.護るべきところを局所化する.
「COBOLエンジニアがいない」なんていうのは幻想.簡単に量産できるよ.プログラム言語としては簡単なんだし.なんのためのその処理かがわからないのは,何を使って作っても一緒w
同時多発か.共通しているのは,手をつけられないクラウドサービスってことかな.
みずほ銀行のシステムに障害が出た場合,金融庁から指導が入ったりするけれど,こういうサービスの場合は,泣き寝入りするしかないんじゃないかな?
Facebookで一時障害、InstagramやOculusなどもアクセスできず 現在は復旧
https://nlab.itmedia.co.jp/nl/articles/2110/05/news096.html
引用:
「モバイルSuica」「モバイルPASMO」、Apple Payでチャージできない障害 Appleのネットワーク障害が原因か
https://www.itmedia.co.jp/business/articles/2110/05/news090.html
引用:
「Outlook」でアクセス障害 「最近の設定変更が原因」 Teamsなど別アプリでも影響か
https://www.itmedia.co.jp/news/articles/2110/05/news089.html
引用:
みずほ銀行のシステムに障害が出た場合,金融庁から指導が入ったりするけれど,こういうサービスの場合は,泣き寝入りするしかないんじゃないかな?
Facebookで一時障害、InstagramやOculusなどもアクセスできず 現在は復旧
https://nlab.itmedia.co.jp/nl/articles/2110/05/news096.html
引用:
10月5日の未明から朝にかけ、FacebookやInstagramなどで一時ログインできないなどの障害が発生していました。5日11時時点では既に復旧済み。
「モバイルSuica」「モバイルPASMO」、Apple Payでチャージできない障害 Appleのネットワーク障害が原因か
https://www.itmedia.co.jp/business/articles/2110/05/news090.html
引用:
JR東日本は10月5日、モバイルSuicaのiOS版でアプリ経由のチャージや定期券の購入ができない障害が発生していると発表した。影響範囲などについては調査中。復旧のめどは立っておらず、同社は券売機でのチャージを呼び掛けている。
「Outlook」でアクセス障害 「最近の設定変更が原因」 Teamsなど別アプリでも影響か
https://www.itmedia.co.jp/news/articles/2110/05/news089.html
引用:
米Microsoftが提供するメールクライアント「Outlook」で10月5日朝(日本時間)から、メールボックスにアクセスできない障害が発生している。Twitterでは午前8時ごろから「Outlook障害でメールを送れない」「仕事に支障が出る」などの報告が相次いでいる
こういうの別の日にしてほしいなぁ.
「サイバー攻撃ではない」 大規模なアクセス障害に障害元の米Akamaiがコメント
https://www.itmedia.co.jp/news/articles/2107/23/news028.html
引用:
一気に複数システムがダウンすることはありえないので,そういうと時は広域障害を疑って,ツイッターで「繋がらない」で検索すると,情報が見えてくる.
逆に回復の兆しが見えた時は「繋がった」で検索する.これ,プチ情報.
「サイバー攻撃ではない」 大規模なアクセス障害に障害元の米Akamaiがコメント
https://www.itmedia.co.jp/news/articles/2107/23/news028.html
引用:
7月23日午前1時ごろから午前2時ごろにかけて発生した、オリンピックや日本航空(JAL)などの公式サイトや、オンラインサービス「PlayStation Network」(PSN)のアクセス障害。問題の原因になったとみられるサービスを手掛ける米Akamai Technologiesは、障害について「Akamaiへのサイバー攻撃によるものではないことを確認した」と同社のTwitterアカウントで明らかにした。
一気に複数システムがダウンすることはありえないので,そういうと時は広域障害を疑って,ツイッターで「繋がらない」で検索すると,情報が見えてくる.
逆に回復の兆しが見えた時は「繋がった」で検索する.これ,プチ情報.
こういう話.
「ネット予約」はなぜ落ちるのか どうすれば落ちないのか
https://www.itmedia.co.jp/news/articles/2105/21/news094.html
引用: 予約だけじゃなくて,テレビで紹介された地方のスイーツショップの公式サイトとか,中小企業が運営しているサーバは簡単に接続できなくなる.このサーバもそう.
大量にアクセスがある場合,どう処理するかは古典的なものは静的コンテンツと動的コンテンツを分けること.並列にスケールすることというのがあるけれど,急に来て一時的なものは予測不可能なので,AkamaiなどのCDNを使うのが良いでしょう.お金がかかるけれど.まぁ,とはいえ普通一時的なものだから,殴られっぱなしで時を待つ対処がおおいかな.実はプログラムの効率化(画面遷移・SQL最適化)などもあるんだけれど.
最近の大規模予約システムで問題が出なかったのは,2019年のラグビーと,2019年の東京オリンピックの抽選申し込み.
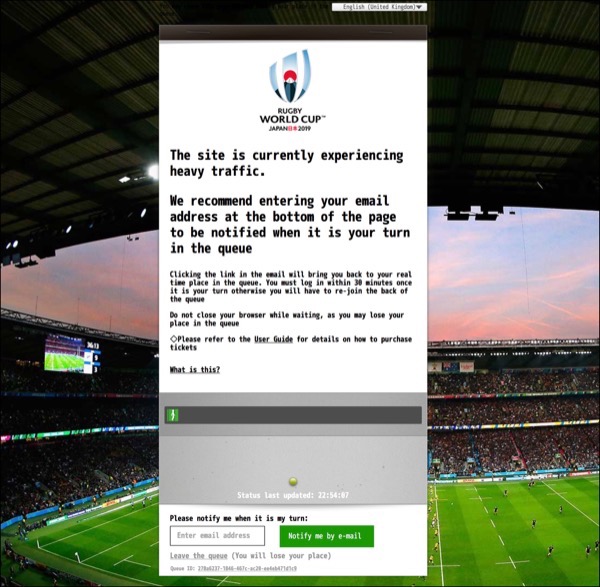

こうして並べてみると,同じシステムのように見えるな.これはアクセスしてきた人を待ち行列に入れて処理する方式.ここまでくると大規模システムじゃないと導入は無理かな.
やっぱり処理性能を見積もっていて,それ以上になったらSorryに流すのが基本か.
「ネット予約」はなぜ落ちるのか どうすれば落ちないのか
https://www.itmedia.co.jp/news/articles/2105/21/news094.html
引用:
コロナ向け予防接種の予約システムで、「ネットのシステムが混雑で落ちた」という話が問題視された。話題の製品が出るたびに「ネットショップが落ちる」という話も出る。
大量にアクセスがある場合,どう処理するかは古典的なものは静的コンテンツと動的コンテンツを分けること.並列にスケールすることというのがあるけれど,急に来て一時的なものは予測不可能なので,AkamaiなどのCDNを使うのが良いでしょう.お金がかかるけれど.まぁ,とはいえ普通一時的なものだから,殴られっぱなしで時を待つ対処がおおいかな.実はプログラムの効率化(画面遷移・SQL最適化)などもあるんだけれど.
最近の大規模予約システムで問題が出なかったのは,2019年のラグビーと,2019年の東京オリンピックの抽選申し込み.
こうして並べてみると,同じシステムのように見えるな.これはアクセスしてきた人を待ち行列に入れて処理する方式.ここまでくると大規模システムじゃないと導入は無理かな.
やっぱり処理性能を見積もっていて,それ以上になったらSorryに流すのが基本か.
WD製NASに脆弱性、今すぐネット切断を。フルリセットで全データ消失
https://news.yahoo.co.jp/articles/e993eb400fd08d4346b22d89887d16e079465f81
引用: 10年前の商品だけれど,まだ使っている人が多くいる点について,どう評価するか. こういう簡易NASは当時流行った気がする.
引用:
https://news.yahoo.co.jp/articles/e993eb400fd08d4346b22d89887d16e079465f81
引用:
米Western Digital(WD)は25日(現地時間)、同社が2010年に出荷したNAS「My Book Live」および「My Book Live Duo」に脆弱性があるとし、現在も使用しているユーザーはすぐにネットから切断するよう注意を促した。
引用:
また、同製品に使われているPowerPCアーキテクチャ向けにコンパイルされた、「.nttpd,1-ppc-be-t1-z」と呼ばれるLinux ELFバイナリ形式のトロイの木馬がインストールされた形跡があったといい、現在同社は分析のため、このバイナリをVirusTotalにアップロードしたとしている。
もうアンドロイドを使ってないから被害はなかったけれど最近この手の「風が吹いたら桶屋が儲かる」的な障害が多いな.
Android版「Google」アプリ、「繰り返し停止」する不具合を修正した最新版配信
https://internet.watch.impress.co.jp/docs/news/1333640.html
Android版「Google」アプリ、「繰り返し停止」する不具合を修正した最新版配信
https://internet.watch.impress.co.jp/docs/news/1333640.html
1ヶ月ほど前だけれど.
みずほ証券、一時システム障害 ネット取引で売買できず
https://www.jiji.com/jc/article?k=2021051200612
カミさんが,新光証券時代からのお付き合いでNISAの講座を持っていたけれど,使ってないので解約した日がこの障害の当日で,その影響もあったのかどうか,解約した途端に担当営業から電話がかかってきたそうな.
システム障害があったから,営業がスタンバイしていたのかもしれないけれど,担当営業にすぐ伝わるシステムを作っているということかな.CRMの機能なのかね.
みずほ証券、一時システム障害 ネット取引で売買できず
https://www.jiji.com/jc/article?k=2021051200612
カミさんが,新光証券時代からのお付き合いでNISAの講座を持っていたけれど,使ってないので解約した日がこの障害の当日で,その影響もあったのかどうか,解約した途端に担当営業から電話がかかってきたそうな.
システム障害があったから,営業がスタンバイしていたのかもしれないけれど,担当営業にすぐ伝わるシステムを作っているということかな.CRMの機能なのかね.
縁の下の力持ち,的なものは昔からあるけれど,CDNもその1つかな.
AmazonやGitHubなど大規模な障害発生「古き良きインターネットみたいに」
https://ledge.ai/fastly0608/
画像やCSSなどの静的ファイルはCDNに置くので,そこに障害があると,昔のWebサイトのようなデザインになってしまうことを,このように表現しているのは興味深い.おっさんセンサーだという自白か?
世界同時多発HP閲覧障害は徐々に復旧…CDN運営会社「Fastly」がプログラム修正を報告
https://hochi.news/articles/20210608-OHT1T51182.html
astlyのCDN障害でSpotify、GitHub、CNNなどがダウン
https://jp.techcrunch.com/2021/06/08/2021-06-08-numerous-popular-websites-are-facing-an-outage/
ここであぶり出されるのは,Fastlyの顧客一覧.まぁ漏洩したのは,Fastlyの営業情報の一部,と言えるから,Akamaiの営業がウォームアップしているかな?
AmazonやGitHubなど大規模な障害発生「古き良きインターネットみたいに」
https://ledge.ai/fastly0608/
画像やCSSなどの静的ファイルはCDNに置くので,そこに障害があると,昔のWebサイトのようなデザインになってしまうことを,このように表現しているのは興味深い.おっさんセンサーだという自白か?
世界同時多発HP閲覧障害は徐々に復旧…CDN運営会社「Fastly」がプログラム修正を報告
https://hochi.news/articles/20210608-OHT1T51182.html
astlyのCDN障害でSpotify、GitHub、CNNなどがダウン
https://jp.techcrunch.com/2021/06/08/2021-06-08-numerous-popular-websites-are-facing-an-outage/
ここであぶり出されるのは,Fastlyの顧客一覧.まぁ漏洩したのは,Fastlyの営業情報の一部,と言えるから,Akamaiの営業がウォームアップしているかな?
今週月曜日,17日から始まった自衛隊による大規模接種会場でのワクチン予約システムの不備.
不備把握もスピード優先 防衛省、システム改修へ―大規模接種
https://www.jiji.com/jc/article?k=2021051801022
引用:
予約が間違った状態でも,本質的にちゃんと予約できた人にしかワクチン接種はできないように仕組み全体ではカバーされている模様.
大規模接種予約システム改修へ 架空情報入力取材に抗議
https://www.tokyo-np.co.jp/article/104935
引用:
朝日新聞出版と毎日新聞が嘘の情報で登録したようだが,これによって正規の人が予約できない状態になっているのは問題だろう.わかっていて業務妨害,国民の不利益だ.
間違って登録してしまった→その人が受けられないので自己責任
意図して偽情報を登録した→枠が消費されたので他の人が受けられない
加藤官房長官曰く「全市区町村が管理する接種券番号含む個人情報をあらかじめ防衛省が把握し、入力情報と照合することが必要」だが「全国民の個人情報を防衛省が把握することが適切なのかという問題」という意見もあったようだ.
完璧なものなんて短期間で最初から作れないから,ワークアラウンド,対策前進で対応していくという方針は問題ないと思う.
メディアも揚げ足取りばかりしていても仕方ない.メディア利用者に注意を呼びかけるくらいの協力をすれば良いのに.
不備把握もスピード優先 防衛省、システム改修へ―大規模接種
https://www.jiji.com/jc/article?k=2021051801022
引用:
自治体から届く接種券に記載された番号や生年月日、市区町村コードを入力する。その際、実在しない情報で予約できることが分かった。ただ、会場では接種券などで本人確認するため、虚偽予約で接種はできない。
予約が間違った状態でも,本質的にちゃんと予約できた人にしかワクチン接種はできないように仕組み全体ではカバーされている模様.
大規模接種予約システム改修へ 架空情報入力取材に抗議
https://www.tokyo-np.co.jp/article/104935
引用:
取材目的で架空情報を使い予約した朝日新聞出版と毎日新聞に対して「悪質な行為であり、極めて遺憾だ。厳重に抗議する」と述べた。
朝日新聞出版と毎日新聞が嘘の情報で登録したようだが,これによって正規の人が予約できない状態になっているのは問題だろう.わかっていて業務妨害,国民の不利益だ.
加藤官房長官曰く「全市区町村が管理する接種券番号含む個人情報をあらかじめ防衛省が把握し、入力情報と照合することが必要」だが「全国民の個人情報を防衛省が把握することが適切なのかという問題」という意見もあったようだ.
完璧なものなんて短期間で最初から作れないから,ワークアラウンド,対策前進で対応していくという方針は問題ないと思う.
メディアも揚げ足取りばかりしていても仕方ない.メディア利用者に注意を呼びかけるくらいの協力をすれば良いのに.
朝からセールスフォースにログインできないと話題.
salesforce_status_japanese
https://www.notion.so/salesforce_status_japanese-df2a619796f0467fa4c083f9a56972ba
スクショ.

09:35現在の公式ステータス
Salesforceステータスへようこそ
https://status.salesforce.com
salesforce_status_japanese
https://www.notion.so/salesforce_status_japanese-df2a619796f0467fa4c083f9a56972ba
スクショ.
09:35現在の公式ステータス
Salesforceステータスへようこそ
https://status.salesforce.com
全体的なまとめはこれ.
データ移行で発生したみずほ銀行のシステム障害についてまとめてみた
https://piyolog.hatenadiary.jp/entry/2021/03/01/055810
引用: ATMの不正防止のため,通帳を吐き出さない仕様.
みずほFG社長「過去の教訓生かせず」、システム障害で対応策
https://jp.reuters.com/article/mizuho-system-idJPKBN2BS0L2
引用: テレビかネットのニュースを見たカミさんは「日立が原因だっていってたよ」と言ってたが,よく読むと3月12日の障害は,日立の機械故障であって,ATMで通帳が取り出せなかった件はまた別.
ちなみに,3月12日の障害はコレ.
みずほ銀でシステム障害、外貨送金300件に遅れ-2週間で4度目
https://www.bloomberg.co.jp/news/articles/2021-03-12/QPURA0T0G1L201
引用: 300件程度で「遅れ」なので,そんなに一般人が認知するほどでも無さそうな.2月28日の障害がなければ小さくお詫びで終わりになるはず.
引用:
みずほ、おわびで「5000円」 クオカード配布―システム障害
https://www.jiji.com/jc/article?k=2021032501259
引用: 現在の金利は0.10%で,100万円を7年定期で預けると税引後5583円.みずほ銀行で通帳が吸い込まれる事案が発生したら,吸い込ませに行くのが正解???かと思っていたけれど,この錬金術は封鎖された模様.
正式な発表はこれ.
システム障害に係る対応状況について - みずほフィナンシャルグループ
https://www.mizuho-fg.co.jp/release/pdf/20210405_2release_jp_1.pdf
2月28日分は,メモリ容量オーバー.
3月3日分は,機器故障
3月7日分は,プログラム不良
3月12日分は,機器故障&切り替え失敗
詳細説明がないけれど,メモリ容量オーバーは「自動拡張設定なし」が原因だった模様.
みずほシステム統合の謎、参加ベンダー「約1000社」の衝撃
https://xtech.nikkei.com/atcl/nxt/column/18/00942/082900007/
引用: MINORIのシステムブロックと担当ベンダを見ても,基盤は日本IBMのようで,日立は外貨の部(今回の3/12障害部分と一致)であって,日本IBMの名前は出てこないな.
基幹は富士通がCOBOLでプログラムを作ってIBMのメインフレーム場で動かし,周辺は日立とかが装置も含めて納入.メインフレームの運用だと,IBMの全面サポートを受けつつも,みずほのシステム部門ががっつりやっているのだろうね.
「自動拡張設定なし」というのもメインフレームっぽいな.使ったらお金はらう契約.
おまけ
ITエンジニア3年でフリーランスに…「得意な技術が1つあれば、それを活かして活躍していける」経験者からのアドバイス
https://news.yahoo.co.jp/articles/ec21b9849554ca01243d6995b034ac30a4d93727
引用: この発言だとMINORIに関わってそうだけれど?,フリーランスということだから,富士通の下請けの孫請けってことかな.もっと階層は深いと思うけれど.(個人事業主の自分ならよくわかります・・・)
https://piyolog.hatenadiary.jp/entry/2021/03/01/055810
引用:
障害発生中は、ATMよりキャッシュカード、通帳が機器から戻されない事象が発生。取り出せなくなる影響を受けた件数は5,244件。
https://jp.reuters.com/article/mizuho-system-idJPKBN2BS0L2
引用:
みずほ銀のシステム障害は、2月28日から約2週間で4件発生した。このうち外貨建て送金に遅れが生じた3月12日の障害は、日立製作所が保有・管理する機器が故障したことで発生。バックアップ機器への切り換えもできなかった。
みずほFGはこの日公表した原因分析で、万一に備えて日立側の早期復旧手順と体制が確立されていなかったと指摘。坂井社長は、責任はすべてみずほにあるとする一方で、「少なくとも(復旧に)7時間もかけることは想定されていない」と発言。「契約の関係にのっとって(日立に)しかるべき対応していく」と述べた。
ちなみに,3月12日の障害はコレ.
https://www.bloomberg.co.jp/news/articles/2021-03-12/QPURA0T0G1L201
引用:
みずほ銀行は12日、システム障害によって300件の外貨建て送金に遅れが出ていたと発表した。
引用:
全国に設置するATMの7割超が停止した2月28日の障害では、利用者のカードや通帳が戻らなくなる不具合が発生した。みずほ銀はこれを受け、通帳を原則返却する仕様にATMを変更したという。
https://www.jiji.com/jc/article?k=2021032501259
引用:
キャッシュカードなどが取り込まれた顧客に対し、おわびとして5000円分のクオカードを送ることを明らかにした。
正式な発表はこれ.
システム障害に係る対応状況について - みずほフィナンシャルグループ
https://www.mizuho-fg.co.jp/release/pdf/20210405_2release_jp_1.pdf
2月28日分は,メモリ容量オーバー.
3月3日分は,機器故障
3月7日分は,プログラム不良
3月12日分は,機器故障&切り替え失敗
詳細説明がないけれど,メモリ容量オーバーは「自動拡張設定なし」が原因だった模様.
みずほシステム統合の謎、参加ベンダー「約1000社」の衝撃
https://xtech.nikkei.com/atcl/nxt/column/18/00942/082900007/
引用:
ミッションクリティカルな運用が求められる。日本IBM製メインフレーム上で稼働させることを決めたが、アプリケーションの開発は旧システム「STEPS」を開発・保守してきた富士通に委託した。「流動性預金は銀行業務の根幹。長年信頼関係を築いてきた富士通が最適と判断した」
基幹は富士通がCOBOLでプログラムを作ってIBMのメインフレーム場で動かし,周辺は日立とかが装置も含めて納入.メインフレームの運用だと,IBMの全面サポートを受けつつも,みずほのシステム部門ががっつりやっているのだろうね.
「自動拡張設定なし」というのもメインフレームっぽいな.使ったらお金はらう契約.
おまけ
ITエンジニア3年でフリーランスに…「得意な技術が1つあれば、それを活かして活躍していける」経験者からのアドバイス
https://news.yahoo.co.jp/articles/ec21b9849554ca01243d6995b034ac30a4d93727
引用:
◆岡山のIT業界は?
向井地:エンジニア歴5年の耒須さん。現在どんなお仕事をされているんですか?
耒須:金融業界のATM関連のシステム開発に携わっています。例えば、ATM利用者の履歴管理をするシステムなどです。
向井地:なるほど。ATMと言えば、最近、某銀行でシステムが動かなくなるというニュースを目にしましたが、耒須さんはどんな思いで聞いていましたか?
耒須:すごくヒヤッとしました。その後のニュースでいろいろと聞いてみると、結果的に、自分が携わっているところではないということでホッとしました。
Macを使っていたらいきなりドコモメールのパスワード入れろと言い出したのでいくら入力しても認証できず.1時間くらい悩んで今は放置.
すると,こんなニュースが.
16日夜からドコモメールで障害 現在は復旧
https://www.itmedia.co.jp/mobile/articles/2103/17/news082.html
引用: 時間的に一致...アカウント消したりしたので被害が大きいなぁと思ったけれど,My docomoにログインして,Mac用にプロファイルをダウンロードしてインストールすれば復帰するので便利.
でも,障害が起きていたことは通知が来てないから,ドコモの公式Twitterをフォローしておくとかが必要なのか.しないな.
すると,こんなニュースが.
16日夜からドコモメールで障害 現在は復旧
https://www.itmedia.co.jp/mobile/articles/2103/17/news082.html
引用:
3月16日21時30分頃から、全国でドコモメールなどのサービスが利用しづらい状況が発生していた。翌17日5時34分頃に回復したが、原因は調査中とのこと。この他に「認証系のサービスでも障害が発生していた」とのことだが、こちらの詳細も調査中としている。
でも,障害が起きていたことは通知が来てないから,ドコモの公式Twitterをフォローしておくとかが必要なのか.しないな.
テレビ番組によっては,トップ扱いだったこのニュース.
LINEの個人情報管理に不備 中国の委託先が接続可能
https://www.asahi.com/articles/ASP3J7K5DP3JUHBI03T.html
引用: オフショアで運用委託している事業があったら,別にそういうことは珍しくないのでは?なんて思ったけれど,問題の本質は法律の改正だった模様.
引用: そういえば,10年前にソフトバンクテレコムが韓国にデータセンタを作ったけれど,そこに個人情報のデータは置いてないのかな? それとも利用者に通知されているのかな.
韓国KT社との合弁によるプサンデータセンターが竣工
https://www.softbank.jp/corp/group/sbtm/news/press/2011/20111208_01/
LINEの個人情報管理に不備 中国の委託先が接続可能
https://www.asahi.com/articles/ASP3J7K5DP3JUHBI03T.html
引用:
無料通信アプリ「LINE」が、中国にある関連会社にシステム開発を委託するなどし、中国人技術者らが日本のサーバーにある利用者の個人情報にアクセスできる状態にしていたことがわかった。LINEはプライバシーポリシーでそうした状況を十分説明しておらず、対応に不備があったと判断。政府の個人情報保護委員会に報告する一方、近く調査のための第三者委員会を立ち上げ、運用の見直しに着手する。
引用:
個人情報保護法は、外国への個人情報の移転や外国からのアクセスに制限をつけ、必要な場合は利用者の同意を得るよう定めている。LINEの規約は「お客様のお住まいの国や地域と同等の個人データ保護法制を持たない第三国にパーソナルデータを移転することがある」などとしているが、[b]昨年6月に成立した改正個人情報保護法(2年以内に施行)に関し、個人情報保護委員会は、原則として移転先の国名などを明記[ib]するよう求めている。
韓国KT社との合弁によるプサンデータセンターが竣工
https://www.softbank.jp/corp/group/sbtm/news/press/2011/20111208_01/
メールを整理していたら,ETCマイレージサービスからのメールが2016年からきてない事が確認.
ETC,全く使ってないのだけれど,気になったのでログインしようとしてみた.
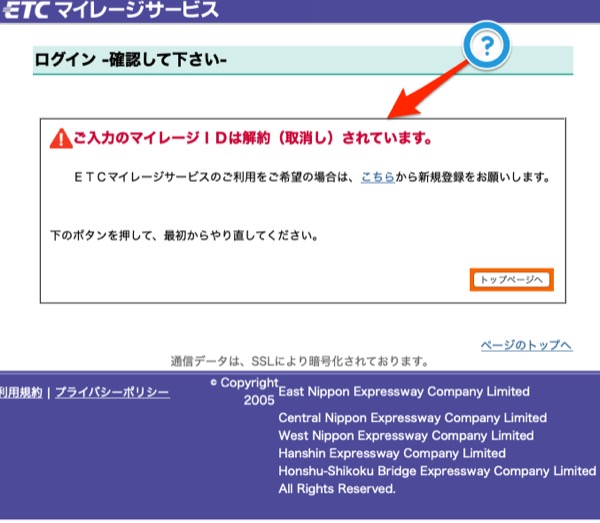
解約されてます!!!

使ってない事が原因か.それは正しい.
6-3.マイレージ登録が取り消されることはありますか。
https://www.smile-etc.jp/guide/qa/06.html
引用:
別のところが気になった.
システム障害に関するお詫び - ETCマイレージサービス
https://www.smile-etc.jp/sysmainte/
頻繁に障害が起こっているようだから,利用のある際にはちゃんとチェックしたいね.
ETC,全く使ってないのだけれど,気になったのでログインしようとしてみた.
解約されてます!!!
使ってない事が原因か.それは正しい.
https://www.smile-etc.jp/guide/qa/06.html
引用:
730日間ETCマイレージサービスのポイント及び還元額に増減がない場合、マイレージ登録は取消しになります。
別のところが気になった.
システム障害に関するお詫び - ETCマイレージサービス
https://www.smile-etc.jp/sysmainte/
頻繁に障害が起こっているようだから,利用のある際にはちゃんとチェックしたいね.
政府主導もあったし,ここ数年でキャッシュレスも進んできた実感もあるけれど,1つの決済方式に依存していると,難民になりそう.
ファミペイ、決済機能を一部停止 システム不具合で - 時事通信社
https://news.yahoo.co.jp/articles/6a47547e8f48dba855147282965f72730311251d
引用: ファミペイも前払いであらかじめチャージしておくやつみたいだけれど,「半額戻ってくる」キャンペーンが中止になったそうだ.延期でなくて中止.
システム不具合のためFamiPay半額戻ってくるキャンペーン、飲食店と家電量販店が中止
https://www.bcnretail.com/market/detail/20210127_210044.html
引用: 障害の原因は飲食店でのキャンペーン決済が多かったからなのかな? 中止と判断した原因は,負荷が原因だとすぐサーバ増強できないから中止,なのかもしれない.
決済系はクラウド上で稼働させてスケールさせるような実装にしてないと思うんだけれどなぁ.どうなんだろう.(考えが古いか)
ファミペイ、決済機能を一部停止 システム不具合で - 時事通信社
https://news.yahoo.co.jp/articles/6a47547e8f48dba855147282965f72730311251d
引用:
ファミリーマート子会社の「ファミマデジタルワン」は27日、スマートフォン決済アプリ「ファミペイ」について、ファミマ以外の店でのQRコードとバーコードによる決済機能を同日午前5時から一時利用停止にしたと発表した。システムの不具合により、26日からこれらの決済が利用できないケースが多発しているため。
27日正午時点でも原因の特定に至っておらず、復旧のめども立っていないという。
システム不具合のためFamiPay半額戻ってくるキャンペーン、飲食店と家電量販店が中止
https://www.bcnretail.com/market/detail/20210127_210044.html
引用:
カテゴリごとにキャンペーン実施期間、FamiPayボーナスで戻る上限額が異なり、ファミリーマートが1月19日~2月1日、ドラッグストアが1月19~25日(終了)、飲食店が1月26日~2月1日、家電量販店が2月2~8日だった。ファミリーマートでは、期間中500円相当を上限にFamiPay決済額の50%が戻ってくる。
決済系はクラウド上で稼働させてスケールさせるような実装にしてないと思うんだけれどなぁ.どうなんだろう.(考えが古いか)
10月31日で契約満了になりインスタンス削除したが,10月5日分のバックアップがあったという件の続報.
バックアップ設定は保守業者がしていた.
クラウドの運用担当者は把握してなかった.
停電で三週間はバックアップが取れてない.
真偽不明の情報だが,参考までに.
定期的にコンフィグレーション・チェックをするのは必要だね.根本的には東証アローズの件も同じだ.
真偽不明の情報だが,参考までに.
定期的にコンフィグレーション・チェックをするのは必要だね.根本的には東証アローズの件も同じだ.
11月下旬のこのニュース.
AWS障害にともない他社サービスもダウン
https://jp.techcrunch.com/2020/11/26/2020-11-25-amazon-web-services-outage-takes-a-portion-of-the-internet-down-with-it/
AWSが11月の大規模障害について説明
https://japan.zdnet.com/article/35163174/
引用: そしてこれ.
AWSで障害、「Nature Remo」「SwitchBot」などに影響 「電気消せない」と嘆く声【追記あり】
https://www.itmedia.co.jp/news/articles/2011/26/news056.html
同じようなことがGoogleでも起きた.
Google Workspaceのダウンは認証システムのストレージクオータが原因 ~Googleが発表
https://forest.watch.impress.co.jp/docs/news/1295179.html
【体験談】Google Homeが全て停止して家の家電が制御できなくなって凍死しかけたお話
https://www.hayaponlog.site/entry/2020/12/14/221759
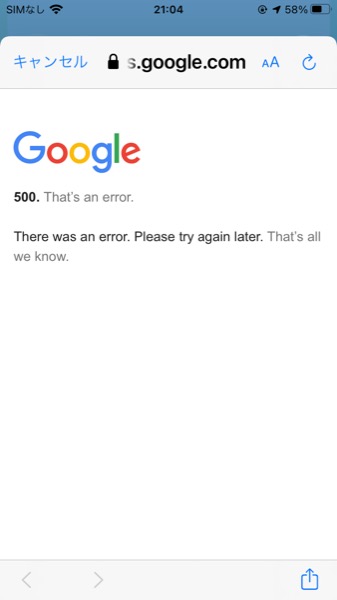
うちの被害はこれ.
ポケモンGoのプレイ中に急にログイン白と通知が来て,ログインしようとするも500エラーがでてしまう問題.
AWS障害にともない他社サービスもダウン
https://jp.techcrunch.com/2020/11/26/2020-11-25-amazon-web-services-outage-takes-a-portion-of-the-internet-down-with-it/
AWSが11月の大規模障害について説明
https://japan.zdnet.com/article/35163174/
引用:
Amazon Web Services(AWS)は、米国時間11月25日に発生した大規模障害についての説明を公開した。この障害では、何千ものサードパーティーのオンラインサービスが数時間にわたって影響を受けた。
AWSで障害、「Nature Remo」「SwitchBot」などに影響 「電気消せない」と嘆く声【追記あり】
https://www.itmedia.co.jp/news/articles/2011/26/news056.html
同じようなことがGoogleでも起きた.
Google Workspaceのダウンは認証システムのストレージクオータが原因 ~Googleが発表
https://forest.watch.impress.co.jp/docs/news/1295179.html
【体験談】Google Homeが全て停止して家の家電が制御できなくなって凍死しかけたお話
https://www.hayaponlog.site/entry/2020/12/14/221759
うちの被害はこれ.
ポケモンGoのプレイ中に急にログイン白と通知が来て,ログインしようとするも500エラーがでてしまう問題.
うーん.
「LINE」で不審な“友だち追加/グループ招待”発生、10月下旬~11月初旬、12万人に影響
https://k-tai.watch.impress.co.jp/docs/news/1290346.html
引用: 去年,スマホに変更したオカンだけれど,近くで操作を教えてくれる人も居ないので,利用に難儀している模様.
そういう人のアカウントにこういうBotが来たら,防ぎようがないかなぁ.
でも,実はバーチャンコミニティの中で不審なメールや通知,アパート経営,ソーラーパネル,リボ払いは良いことがない案内なので無視する事!という口コミが進んでいるので,意外と大丈夫そうだったりはする.
「LINE」で不審な“友だち追加/グループ招待”発生、10月下旬~11月初旬、12万人に影響
https://k-tai.watch.impress.co.jp/docs/news/1290346.html
引用:
LINEは、ユーザーの同意なく「不審なBotが友だちに強制追加される」「不審なBotからグループへ招待される」という事象が発生したことを明らかにした。
そういう人のアカウントにこういうBotが来たら,防ぎようがないかなぁ.
でも,実はバーチャンコミニティの中で不審なメールや通知,アパート経営,ソーラーパネル,リボ払いは良いことがない案内なので無視する事!という口コミが進んでいるので,意外と大丈夫そうだったりはする.
色々と問題があると思う.
「ふくいナビ」バックアップ見つかる 全データ消失のサイト、年内復旧めど
https://www.fukuishimbun.co.jp/articles/-/1209081
引用:
NECキャピタルソリューションの事務手続き瑕疵で,10月31日で契約満了になり仮想サーバが停止されてデータが削除された.
バックアップはないので復旧不可能としていた
やっぱりバックアップがあった.それも10月5日分
なかったと認識していたものが出てきたということは,これはこれで管理できてなかったと同じじゃないかな.
公益財団法人ふくい産業支援センター様の「ふくいナビ」のデータ障害につきまして
https://pdf.irpocket.com/C8793/aMKh/RtZQ/YIJo.pdf
福井県産業情報ネットワーク「ふくいナビ」の 利用者データ(10 月 5 日時点)の復元およびシステムの復旧時期(予定)について
https://pdf.irpocket.com/C8793/aMKh/hLiw/uzzB.pdf
「ふくいナビ」バックアップ見つかる 全データ消失のサイト、年内復旧めど
https://www.fukuishimbun.co.jp/articles/-/1209081
引用:
ふくい産業支援センター(福井県坂井市)は11月18日、サーバー上の全データが消失して使用できなくなったポータルサイト「ふくいナビ」について、12月末までに復旧するめどが立ったことを公表した。
なかったと認識していたものが出てきたということは,これはこれで管理できてなかったと同じじゃないかな.
公益財団法人ふくい産業支援センター様の「ふくいナビ」のデータ障害につきまして
https://pdf.irpocket.com/C8793/aMKh/RtZQ/YIJo.pdf
福井県産業情報ネットワーク「ふくいナビ」の 利用者データ(10 月 5 日時点)の復元およびシステムの復旧時期(予定)について
https://pdf.irpocket.com/C8793/aMKh/hLiw/uzzB.pdf
10月1日,東証のシステムが停止して株取引ができなくなった.この原因は共有ディスクが故障したけれどバックアップ系に切り替わらなかったことが原因とされていたけれど,その切り替わらなかった原因が特定できたそうです.
バックアップ、5年「OFF」 富士通のマニュアルに誤り 東証システム障害
https://mainichi.jp/articles/20201019/k00/00m/020/240000c
引用: 設定ミスということで説明が整理できれば,類似の機械を導入している他社にも説明がしやすい.
10月1日に株式売買システムで発生した障害について
https://www.jpx.co.jp/corporate/news/news-releases/0060/20201019-01.html
東証アローヘッドって,今現在は3代目なんだな.
バックアップ、5年「OFF」 富士通のマニュアルに誤り 東証システム障害
https://mainichi.jp/articles/20201019/k00/00m/020/240000c
引用:
2015年9月のシステムの仕様変更前までは「オフ」でも15秒後に予備に切り替わる仕組みだったが、機器を製造した米メーカーが「オフ」時にはバックアップを作動させない方式に変更。これを富士通が把握せず、「オフ」にして東証に納入。マニュアルにも反映させなかったため、東証は気付かないままシステムを運用していたという。
10月1日に株式売買システムで発生した障害について
https://www.jpx.co.jp/corporate/news/news-releases/0060/20201019-01.html
東証アローヘッドって,今現在は3代目なんだな.
個人的に今はSlackを使ってないので全く影響はないのだけれど,
Slack、約7時間にわたる障害(ほぼ復旧済み)
https://www.itmedia.co.jp/news/articles/2010/06/news050.html
引用:
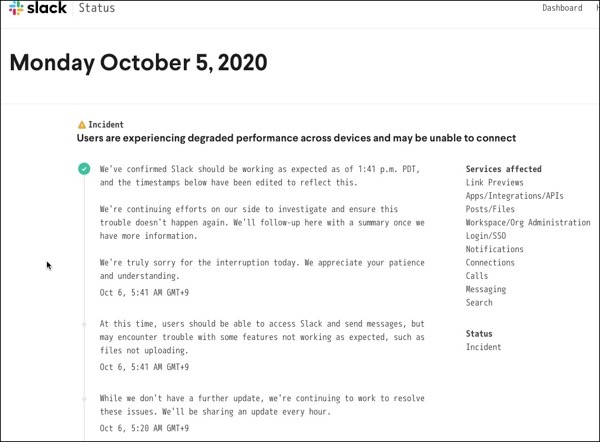
Monday October 5, 2020
https://status.slack.com/2020-10/e8c094cc99aabf64
30分毎くらいに状況を伝達していたのが好感触のよう.
クラウドサービスを利用する際には,稼働状況をレポートするシステムが提供されているかどうかもチェックポイントですな.Slackの場合はAPIがあるそうだ.
https://status.slack.com
今回は日本時間で深夜早朝隊だったので,影響は少なめだろうけれど,監視システムとして使っている場合は仕事にならないね.
Slack、約7時間にわたる障害(ほぼ復旧済み)
https://www.itmedia.co.jp/news/articles/2010/06/news050.html
引用:
企業向けコラボレーションツール「Slack」で、日本時間の10月5日午後11時5分ごろに障害が発生した。Downdetector.comによると、日本だけでなく、米国や欧州を含む広範囲な障害のようだった。運営する米Slackは6日午前4時43分、影響を受けたすべてのサービス(=Slackのすべてのサービス)を更新したと報告し、5時20分にはそれ以上の更新はしないが引き続き問題解決に取り組むとしている。
Monday October 5, 2020
https://status.slack.com/2020-10/e8c094cc99aabf64
30分毎くらいに状況を伝達していたのが好感触のよう.
クラウドサービスを利用する際には,稼働状況をレポートするシステムが提供されているかどうかもチェックポイントですな.Slackの場合はAPIがあるそうだ.
https://status.slack.com
今回は日本時間で深夜早朝隊だったので,影響は少なめだろうけれど,監視システムとして使っている場合は仕事にならないね.
ほとんどは回復した模様.
https://twitter.com/MSFT365Status
引用:
私は,北米では無いから.(たぶんリージョンは日本だとおもう)
https://status.office365.com
ちょっとだけ変わっていたので抜粋.
引用:
https://twitter.com/MSFT365Status
引用:
The majority of services are now recovered for most users. We’re closely monitoring some residual impact for a subset customers located within North America. Please visit https://status.office.com for additional information.
現在、大部分のサービスは、ほとんどのユーザーが復旧しています。北米内の一部のお客様については、一部の影響が残っているかどうかを注意深く監視しています。詳細については、https://status.office.com をご覧ください。
私は,北米では無いから.(たぶんリージョンは日本だとおもう)
https://status.office365.com
ちょっとだけ変わっていたので抜粋.
引用:
Current status: We have confirmed via our monitoring that the majority of services have recovered for most customers. However, we continue to see a small subset of customers whose tenants are located in North America region who are still impacted. We're now investigating mitigation steps for those customers who are still affected.
現在の状況 モニタリングの結果、ほとんどのお客様のサービスが復旧していることを確認しております。しかし、北米地域にテナントがあるお客様の中には、まだ影響を受けている一部のお客様がいます。現在、影響を受けているお客様への緩和策を検討しています。
全世界的に新規ログオンができなくなっている模様.今のログオン情愛は保持しなければいけないな.
10時出社の人とは連絡取れないかもな...
対応状況を確認するためのサイト.
Microsoft 365 Status
https://twitter.com/MSFT365Status
引用:
障害による問題のあるサービスを確認する情報.
Microsoft 365 Service health status
https://status.office365.com
引用:
リージョン別,機能別に状態がわかる.
Azure の状態
https://status.azure.com/ja-jp/status
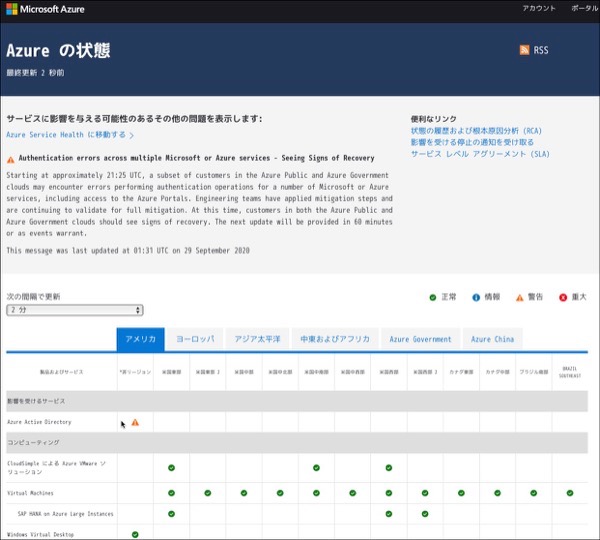
引用: Active Directoryに障害が出ているのであれば,これが単一障害点か.キャッシュログオンで救われているけれど...
10時出社の人とは連絡取れないかもな...
対応状況を確認するためのサイト.
Microsoft 365 Status
https://twitter.com/MSFT365Status
引用:
We're investigating an issue affecting access to multiple Microsoft 365 services. We're working to identify the full impact and will provide more information shortly.
複数の Microsoft 365 サービスへのアクセスに影響を与える問題を調査しています。影響の全容を特定するための作業を行っており、近日中に詳細な情報を提供します。
We’re rerouting traffic to alternate infrastructure to improve the user experience while we continue to investigate the issue. Please visit http://status.office.com for additional information.
問題の調査を継続している間、ユーザー体験を向上させるために、トラフィックを別のインフラストラクチャに再ルーティングしています。詳細については、http://status.office.com をご覧ください。
We’re seeing improvement for multiple services after applying mitigation steps and we’ll continue monitoring the services to ensure full recovery. Please visit http://status.office.com for additional information.
緩和措置を適用した後、複数のサービスで改善が確認されており、完全な回復を確実にするためにサービスの監視を継続します。詳細については、http://status.office.com をご覧ください。
障害による問題のあるサービスを確認する情報.
Microsoft 365 Service health status
https://status.office365.com
引用:
Title: Can't access Microsoft 365 services
User Impact: Users may be unable to access multiple Microsoft 365 services.
More info: Users may be unable to access any services that leverage Azure Active Directory (AAD) including Outlook, Microsoft Teams and Teams Live Events as well as Office.com. Additionally, Power Platform and Dynamics365 properties are also affected by this incident.
Existing customer sessions are not impacted and any user who is logged in to an existing session would be able to continue their sessions.
Current status: Our mitigation strategy was successful in allowing users to sign into the previously impacted services. Our internal monitoring has validated this recovery and we have received positive confirmation from customer reports. We’ll continue to monitor the service and provide updates on full recovery to remaining impacted users.
Scope of impact: Any user may experience access problems for Microsoft 365 services.
詳細はこちらをご覧ください。Outlook、Microsoft Teams、Teams、Teams Live Events、Office.comなど、Azure Active Directory (AAD)を利用しているサービスにアクセスできなくなる可能性があります。また、Power PlatformおよびDynamics365のプロパティもこのインシデントの影響を受けます。
既存のお客様のセッションに影響はなく、既存のセッションにログインしているユーザーはセッションを継続することができます。
現在の状況 緩和策により、影響を受けていたサービスにサインインできるようになりました。当社の内部監視により、この復旧が確認され、お客様のレポートから肯定的な確認が得られています。今後もサービスの監視を継続し、影響を受けた残りのユーザーに完全復旧に関する最新情報を提供していきます。
影響の範囲。どのようなユーザーでも、Microsoft 365 サービスへのアクセス問題が発生する可能性があります。
リージョン別,機能別に状態がわかる.
Azure の状態
https://status.azure.com/ja-jp/status
引用:
警告 Authentication errors across multiple Microsoft or Azure services - Seeing Signs of Recovery
Starting at approximately 21:25 UTC, a subset of customers in the Azure Public and Azure Government clouds may encounter errors performing authentication operations for a number of Microsoft or Azure services, including access to the Azure Portals. Engineering teams have applied mitigation steps and are continuing to validate for full mitigation. At this time, customers in both the Azure Public and Azure Government clouds should see signs of recovery. The next update will be provided in 60 minutes or as events warrant.
This message was last updated at 01:31 UTC on 29 September 2020
警告 複数のMicrosoftまたはAzureサービスにまたがる認証エラー - 復旧の兆しを見る
UTC 21:25頃から、Azure PublicおよびAzure Governmentクラウドの一部の顧客が、Azure Portalsへのアクセスを含む多くのMicrosoftまたはAzureサービスの認証操作を実行する際にエラーが発生する可能性があります。エンジニアリングチームは、緩和措置を適用し、完全な緩和のための検証を継続しています。現時点では、Azure Public クラウドと Azure Government クラウドの両方のお客様に回復の兆しが見られるはずです。次回の更新は、60分以内、またはイベントに応じて提供されます。
このメッセージの最終更新は 2020 年 9 月 29 日 01:31 UTC です。