



ブログ - 迷惑メールの統計分析 20220923現在
この記事に感化されて...
詐欺サイトのドメイン、この半年で「.cn」「.com」に続き突然「.ci」が急増【デジタルアーツ調べ】
https://webtan.impress.co.jp/n/2022/09/09/43299
うちに毎日来る迷惑メールのストックです.
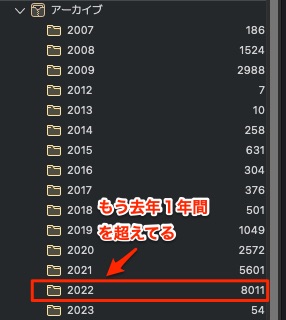
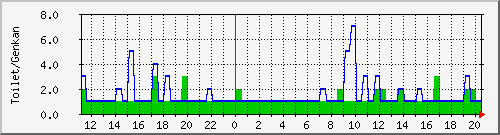
今年はすでに去年2021年を超えていますね.
取り急ぎ,Fromアドレスを調べてみました.
Fromアドレスは次のようにして抽出. そして件数を調べる.
結果がこれ.
最近来なくなったけれど,メルカリが多かったのね.
トップドメインごとの集計をしてみる.
まずは抽出.
そしてトップ30をリスト.
次に,誘導先のURLを抽出してみる.今回はHTMLメールの本文がBASE64の場合は考慮してない...
一旦これでhttp|httpsで始まる行が取り出せた.
次に,URLのサブディレクトリ以下を消す.
ここまででURLだけが取り出せている.
次に,TLDを取り出す.
結果のトップ20を表示.
グラフにしてみた.
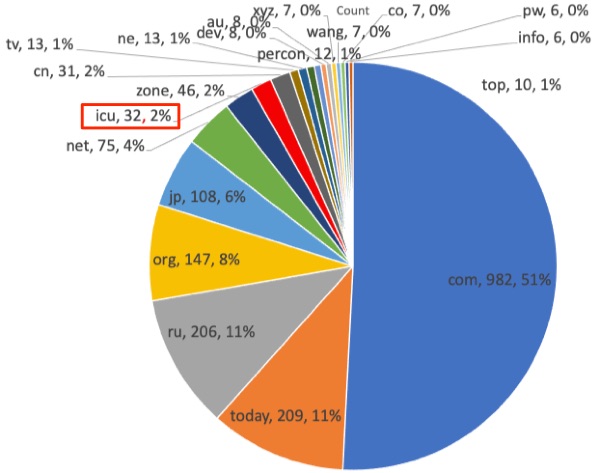
ぐちゃぐちゃだ...ちなみに,うちではicuは2%でした.
詐欺サイトのドメイン、この半年で「.cn」「.com」に続き突然「.ci」が急増【デジタルアーツ調べ】
https://webtan.impress.co.jp/n/2022/09/09/43299
うちに毎日来る迷惑メールのストックです.
今年はすでに去年2021年を超えていますね.
取り急ぎ,Fromアドレスを調べてみました.
Fromアドレスは次のようにして抽出.
grep "^From:" *.eml -h |sort |sed 's/[<\|>|\ ]//g'|sed 's/From://g'|🆑
sed 's/@/,@/g' |rev|cut -d "," -f 1|rev|sort|grep "@"|sort > ../FromAddress.txt🆑
・メールファイルから,先頭からFrom:が含まれている行を抽出.
・メアドの前後にある<>と半角スペースを置き換え.
・"From:"という文字を消す.
・"@"を",@"に置き換え(メアドとドメインをCSV化するため)
・revで文字を逆にする.
・逆にされたら1列目にドメイン名が来ているのでcutで行を取り出す.
・取り出した行を再度revで元に戻す.
・"@"が含まれている行だけ抽出.
uniq -c FromAddress.txt|sort -r > ../FromAddressDomainUniq.txt🆑
結果がこれ.
$ head -n 20 FromAddressDomainUniq.txt🆑
646 @mercari.jp
534 @au.com
492 @mega.nz
296 @visa.co.jp
140 @aeon.co.jp
135 @amazon.co.jp
134 @jcb.co.jp
114 @私の管理するドメイン
96 @mastercard.co.jp
63 @eki-net.com
60 @Amazon.co.jp
52 @eva.hi-ho.ne.jp
50 @saisoncard.co.jp
40 @smbc.co.jp
34 @ts3card.com
32 @dn.smbc.co.jp
27 @connect.auone.jp
26 @mobilesuica.com
23 @hotmail.com
21 @gmail.com
$トップドメインごとの集計をしてみる.
まずは抽出.
grep "^From:" *.eml -h |sort |sed 's/[<\|>|\ ]//g'|sed 's/From://g'|🆑
sed 's/@/,@/g' |rev|sed 's/\./,/g'|cut -d "," -f 1|rev|sort|uniq -c|🆑
sort -r > TLD.txt🆑
そしてトップ30をリスト.
$ head -n 30 TLD.txt🆑
2273 jp
1514 com
784 cn
510 net
492 nz
324 org
68 top
20 word
20 us
20 asia
19 cc
18 mobi
18 me
18 hk
17 shop
17 info
16 co
15 biz
13 ca
10 ru
10 cOm
7 jo
7 il
7 de
5 localdomain
5 ir
5 fr
4 xyz
4 uk
4 nf
$次に,誘導先のURLを抽出してみる.今回はHTMLメールの本文がBASE64の場合は考慮してない...
grep "http" *.eml -h |sed 's/http/\nhttp/g'|grep "http"|grep -v -e ".jpg" -e ".gif"|
sed 's/[\?|\&|\=\"]/\n/g' |grep "^http"|sort -r > http.txt
・httpのキーワードのある行を抽出.
・httpの前に改行文字を入れる.
・JPGとGIFファイルへのリンクを削除.
・URLのドメイン以下を削除するため,区切り文字(/?&)などを改行と置き換える.
次に,URLのサブディレクトリ以下を消す.
cat ../http.txt|sed 's/\/\//@@@/g'|sed 's/\//\n'/g |sort|sed 's/@@@/\/\//g'|
grep -e "http:" -e "https:" > http1.txt
・一旦//を@@@に置き換えて/を改行にして再度@@@を//に戻している.
次に,TLDを取り出す.
rev http1.txt|cut -d "." -f 1|rev|sort|uniq -c |sort -r > http2.txt
・revで文字を逆転させ,列区切り文字を"."として1列目を取り出し,再度文字を逆転している.
$ head -n 20 http2.txt🆑
982 com
209 today
206 ru
147 org
108 jp
75 net
46 zone
32 icu 🈁
31 cn
13 tv
13 ne
12 percon
10 top
8 dev
8 au
7 xyz
7 wang
7 co
6 pw
6 info
グラフにしてみた.
ぐちゃぐちゃだ...ちなみに,うちではicuは2%でした.